Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- Independent vs. Dependent Variables | Definition & Examples

Independent vs. Dependent Variables | Definition & Examples
Published on February 3, 2022 by Pritha Bhandari . Revised on June 22, 2023.
In research, variables are any characteristics that can take on different values, such as height, age, temperature, or test scores.
Researchers often manipulate or measure independent and dependent variables in studies to test cause-and-effect relationships.
- The independent variable is the cause. Its value is independent of other variables in your study.
- The dependent variable is the effect. Its value depends on changes in the independent variable.
Your independent variable is the temperature of the room. You vary the room temperature by making it cooler for half the participants, and warmer for the other half.
Table of contents
What is an independent variable, types of independent variables, what is a dependent variable, identifying independent vs. dependent variables, independent and dependent variables in research, visualizing independent and dependent variables, other interesting articles, frequently asked questions about independent and dependent variables.
An independent variable is the variable you manipulate or vary in an experimental study to explore its effects. It’s called “independent” because it’s not influenced by any other variables in the study.
Independent variables are also called:
- Explanatory variables (they explain an event or outcome)
- Predictor variables (they can be used to predict the value of a dependent variable)
- Right-hand-side variables (they appear on the right-hand side of a regression equation).
These terms are especially used in statistics , where you estimate the extent to which an independent variable change can explain or predict changes in the dependent variable.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

There are two main types of independent variables.
- Experimental independent variables can be directly manipulated by researchers.
- Subject variables cannot be manipulated by researchers, but they can be used to group research subjects categorically.
Experimental variables
In experiments, you manipulate independent variables directly to see how they affect your dependent variable. The independent variable is usually applied at different levels to see how the outcomes differ.
You can apply just two levels in order to find out if an independent variable has an effect at all.
You can also apply multiple levels to find out how the independent variable affects the dependent variable.
You have three independent variable levels, and each group gets a different level of treatment.
You randomly assign your patients to one of the three groups:
- A low-dose experimental group
- A high-dose experimental group
- A placebo group (to research a possible placebo effect )

A true experiment requires you to randomly assign different levels of an independent variable to your participants.
Random assignment helps you control participant characteristics, so that they don’t affect your experimental results. This helps you to have confidence that your dependent variable results come solely from the independent variable manipulation.
Subject variables
Subject variables are characteristics that vary across participants, and they can’t be manipulated by researchers. For example, gender identity, ethnicity, race, income, and education are all important subject variables that social researchers treat as independent variables.
It’s not possible to randomly assign these to participants, since these are characteristics of already existing groups. Instead, you can create a research design where you compare the outcomes of groups of participants with characteristics. This is a quasi-experimental design because there’s no random assignment. Note that any research methods that use non-random assignment are at risk for research biases like selection bias and sampling bias .
Your independent variable is a subject variable, namely the gender identity of the participants. You have three groups: men, women and other.
Your dependent variable is the brain activity response to hearing infant cries. You record brain activity with fMRI scans when participants hear infant cries without their awareness.
A dependent variable is the variable that changes as a result of the independent variable manipulation. It’s the outcome you’re interested in measuring, and it “depends” on your independent variable.
In statistics , dependent variables are also called:
- Response variables (they respond to a change in another variable)
- Outcome variables (they represent the outcome you want to measure)
- Left-hand-side variables (they appear on the left-hand side of a regression equation)
The dependent variable is what you record after you’ve manipulated the independent variable. You use this measurement data to check whether and to what extent your independent variable influences the dependent variable by conducting statistical analyses.
Based on your findings, you can estimate the degree to which your independent variable variation drives changes in your dependent variable. You can also predict how much your dependent variable will change as a result of variation in the independent variable.
Distinguishing between independent and dependent variables can be tricky when designing a complex study or reading an academic research paper .
A dependent variable from one study can be the independent variable in another study, so it’s important to pay attention to research design .
Here are some tips for identifying each variable type.
Recognizing independent variables
Use this list of questions to check whether you’re dealing with an independent variable:
- Is the variable manipulated, controlled, or used as a subject grouping method by the researcher?
- Does this variable come before the other variable in time?
- Is the researcher trying to understand whether or how this variable affects another variable?
Recognizing dependent variables
Check whether you’re dealing with a dependent variable:
- Is this variable measured as an outcome of the study?
- Is this variable dependent on another variable in the study?
- Does this variable get measured only after other variables are altered?
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
Independent and dependent variables are generally used in experimental and quasi-experimental research.
Here are some examples of research questions and corresponding independent and dependent variables.
| Research question | Independent variable | Dependent variable(s) |
|---|---|---|
| Do tomatoes grow fastest under fluorescent, incandescent, or natural light? | ||
| What is the effect of intermittent fasting on blood sugar levels? | ||
| Is medical marijuana effective for pain reduction in people with chronic pain? | ||
| To what extent does remote working increase job satisfaction? |
For experimental data, you analyze your results by generating descriptive statistics and visualizing your findings. Then, you select an appropriate statistical test to test your hypothesis .
The type of test is determined by:
- your variable types
- level of measurement
- number of independent variable levels.
You’ll often use t tests or ANOVAs to analyze your data and answer your research questions.
In quantitative research , it’s good practice to use charts or graphs to visualize the results of studies. Generally, the independent variable goes on the x -axis (horizontal) and the dependent variable on the y -axis (vertical).
The type of visualization you use depends on the variable types in your research questions:
- A bar chart is ideal when you have a categorical independent variable.
- A scatter plot or line graph is best when your independent and dependent variables are both quantitative.
To inspect your data, you place your independent variable of treatment level on the x -axis and the dependent variable of blood pressure on the y -axis.
You plot bars for each treatment group before and after the treatment to show the difference in blood pressure.

If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Degrees of freedom
- Null hypothesis
- Discourse analysis
- Control groups
- Mixed methods research
- Non-probability sampling
- Quantitative research
- Ecological validity
Research bias
- Rosenthal effect
- Implicit bias
- Cognitive bias
- Selection bias
- Negativity bias
- Status quo bias
An independent variable is the variable you manipulate, control, or vary in an experimental study to explore its effects. It’s called “independent” because it’s not influenced by any other variables in the study.
A dependent variable is what changes as a result of the independent variable manipulation in experiments . It’s what you’re interested in measuring, and it “depends” on your independent variable.
In statistics, dependent variables are also called:
Determining cause and effect is one of the most important parts of scientific research. It’s essential to know which is the cause – the independent variable – and which is the effect – the dependent variable.
You want to find out how blood sugar levels are affected by drinking diet soda and regular soda, so you conduct an experiment .
- The type of soda – diet or regular – is the independent variable .
- The level of blood sugar that you measure is the dependent variable – it changes depending on the type of soda.
No. The value of a dependent variable depends on an independent variable, so a variable cannot be both independent and dependent at the same time. It must be either the cause or the effect, not both!
Yes, but including more than one of either type requires multiple research questions .
For example, if you are interested in the effect of a diet on health, you can use multiple measures of health: blood sugar, blood pressure, weight, pulse, and many more. Each of these is its own dependent variable with its own research question.
You could also choose to look at the effect of exercise levels as well as diet, or even the additional effect of the two combined. Each of these is a separate independent variable .
To ensure the internal validity of an experiment , you should only change one independent variable at a time.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bhandari, P. (2023, June 22). Independent vs. Dependent Variables | Definition & Examples. Scribbr. Retrieved September 3, 2024, from https://www.scribbr.com/methodology/independent-and-dependent-variables/
Is this article helpful?

Pritha Bhandari
Other students also liked, guide to experimental design | overview, steps, & examples, explanatory and response variables | definitions & examples, confounding variables | definition, examples & controls, "i thought ai proofreading was useless but..".
I've been using Scribbr for years now and I know it's a service that won't disappoint. It does a good job spotting mistakes”
Research Variables 101
Independent variables, dependent variables, control variables and more
By: Derek Jansen (MBA) | Expert Reviewed By: Kerryn Warren (PhD) | January 2023
If you’re new to the world of research, especially scientific research, you’re bound to run into the concept of variables , sooner or later. If you’re feeling a little confused, don’t worry – you’re not the only one! Independent variables, dependent variables, confounding variables – it’s a lot of jargon. In this post, we’ll unpack the terminology surrounding research variables using straightforward language and loads of examples .
Overview: Variables In Research
| 1. ? 2. variables 3. variables 4. variables | 5. variables |
What (exactly) is a variable?
The simplest way to understand a variable is as any characteristic or attribute that can experience change or vary over time or context – hence the name “variable”. For example, the dosage of a particular medicine could be classified as a variable, as the amount can vary (i.e., a higher dose or a lower dose). Similarly, gender, age or ethnicity could be considered demographic variables, because each person varies in these respects.
Within research, especially scientific research, variables form the foundation of studies, as researchers are often interested in how one variable impacts another, and the relationships between different variables. For example:
- How someone’s age impacts their sleep quality
- How different teaching methods impact learning outcomes
- How diet impacts weight (gain or loss)
As you can see, variables are often used to explain relationships between different elements and phenomena. In scientific studies, especially experimental studies, the objective is often to understand the causal relationships between variables. In other words, the role of cause and effect between variables. This is achieved by manipulating certain variables while controlling others – and then observing the outcome. But, we’ll get into that a little later…
The “Big 3” Variables
Variables can be a little intimidating for new researchers because there are a wide variety of variables, and oftentimes, there are multiple labels for the same thing. To lay a firm foundation, we’ll first look at the three main types of variables, namely:
- Independent variables (IV)
- Dependant variables (DV)
- Control variables
What is an independent variable?
Simply put, the independent variable is the “ cause ” in the relationship between two (or more) variables. In other words, when the independent variable changes, it has an impact on another variable.
For example:
- Increasing the dosage of a medication (Variable A) could result in better (or worse) health outcomes for a patient (Variable B)
- Changing a teaching method (Variable A) could impact the test scores that students earn in a standardised test (Variable B)
- Varying one’s diet (Variable A) could result in weight loss or gain (Variable B).
It’s useful to know that independent variables can go by a few different names, including, explanatory variables (because they explain an event or outcome) and predictor variables (because they predict the value of another variable). Terminology aside though, the most important takeaway is that independent variables are assumed to be the “cause” in any cause-effect relationship. As you can imagine, these types of variables are of major interest to researchers, as many studies seek to understand the causal factors behind a phenomenon.
Need a helping hand?
What is a dependent variable?
While the independent variable is the “ cause ”, the dependent variable is the “ effect ” – or rather, the affected variable . In other words, the dependent variable is the variable that is assumed to change as a result of a change in the independent variable.
Keeping with the previous example, let’s look at some dependent variables in action:
- Health outcomes (DV) could be impacted by dosage changes of a medication (IV)
- Students’ scores (DV) could be impacted by teaching methods (IV)
- Weight gain or loss (DV) could be impacted by diet (IV)
In scientific studies, researchers will typically pay very close attention to the dependent variable (or variables), carefully measuring any changes in response to hypothesised independent variables. This can be tricky in practice, as it’s not always easy to reliably measure specific phenomena or outcomes – or to be certain that the actual cause of the change is in fact the independent variable.
As the adage goes, correlation is not causation . In other words, just because two variables have a relationship doesn’t mean that it’s a causal relationship – they may just happen to vary together. For example, you could find a correlation between the number of people who own a certain brand of car and the number of people who have a certain type of job. Just because the number of people who own that brand of car and the number of people who have that type of job is correlated, it doesn’t mean that owning that brand of car causes someone to have that type of job or vice versa. The correlation could, for example, be caused by another factor such as income level or age group, which would affect both car ownership and job type.
To confidently establish a causal relationship between an independent variable and a dependent variable (i.e., X causes Y), you’ll typically need an experimental design , where you have complete control over the environmen t and the variables of interest. But even so, this doesn’t always translate into the “real world”. Simply put, what happens in the lab sometimes stays in the lab!
As an alternative to pure experimental research, correlational or “ quasi-experimental ” research (where the researcher cannot manipulate or change variables) can be done on a much larger scale more easily, allowing one to understand specific relationships in the real world. These types of studies also assume some causality between independent and dependent variables, but it’s not always clear. So, if you go this route, you need to be cautious in terms of how you describe the impact and causality between variables and be sure to acknowledge any limitations in your own research.

What is a control variable?
In an experimental design, a control variable (or controlled variable) is a variable that is intentionally held constant to ensure it doesn’t have an influence on any other variables. As a result, this variable remains unchanged throughout the course of the study. In other words, it’s a variable that’s not allowed to vary – tough life 🙂
As we mentioned earlier, one of the major challenges in identifying and measuring causal relationships is that it’s difficult to isolate the impact of variables other than the independent variable. Simply put, there’s always a risk that there are factors beyond the ones you’re specifically looking at that might be impacting the results of your study. So, to minimise the risk of this, researchers will attempt (as best possible) to hold other variables constant . These factors are then considered control variables.
Some examples of variables that you may need to control include:
- Temperature
- Time of day
- Noise or distractions
Which specific variables need to be controlled for will vary tremendously depending on the research project at hand, so there’s no generic list of control variables to consult. As a researcher, you’ll need to think carefully about all the factors that could vary within your research context and then consider how you’ll go about controlling them. A good starting point is to look at previous studies similar to yours and pay close attention to which variables they controlled for.
Of course, you won’t always be able to control every possible variable, and so, in many cases, you’ll just have to acknowledge their potential impact and account for them in the conclusions you draw. Every study has its limitations , so don’t get fixated or discouraged by troublesome variables. Nevertheless, always think carefully about the factors beyond what you’re focusing on – don’t make assumptions!

Other types of variables
As we mentioned, independent, dependent and control variables are the most common variables you’ll come across in your research, but they’re certainly not the only ones you need to be aware of. Next, we’ll look at a few “secondary” variables that you need to keep in mind as you design your research.
- Moderating variables
- Mediating variables
- Confounding variables
- Latent variables
Let’s jump into it…
What is a moderating variable?
A moderating variable is a variable that influences the strength or direction of the relationship between an independent variable and a dependent variable. In other words, moderating variables affect how much (or how little) the IV affects the DV, or whether the IV has a positive or negative relationship with the DV (i.e., moves in the same or opposite direction).
For example, in a study about the effects of sleep deprivation on academic performance, gender could be used as a moderating variable to see if there are any differences in how men and women respond to a lack of sleep. In such a case, one may find that gender has an influence on how much students’ scores suffer when they’re deprived of sleep.
It’s important to note that while moderators can have an influence on outcomes , they don’t necessarily cause them ; rather they modify or “moderate” existing relationships between other variables. This means that it’s possible for two different groups with similar characteristics, but different levels of moderation, to experience very different results from the same experiment or study design.
What is a mediating variable?
Mediating variables are often used to explain the relationship between the independent and dependent variable (s). For example, if you were researching the effects of age on job satisfaction, then education level could be considered a mediating variable, as it may explain why older people have higher job satisfaction than younger people – they may have more experience or better qualifications, which lead to greater job satisfaction.
Mediating variables also help researchers understand how different factors interact with each other to influence outcomes. For instance, if you wanted to study the effect of stress on academic performance, then coping strategies might act as a mediating factor by influencing both stress levels and academic performance simultaneously. For example, students who use effective coping strategies might be less stressed but also perform better academically due to their improved mental state.
In addition, mediating variables can provide insight into causal relationships between two variables by helping researchers determine whether changes in one factor directly cause changes in another – or whether there is an indirect relationship between them mediated by some third factor(s). For instance, if you wanted to investigate the impact of parental involvement on student achievement, you would need to consider family dynamics as a potential mediator, since it could influence both parental involvement and student achievement simultaneously.

What is a confounding variable?
A confounding variable (also known as a third variable or lurking variable ) is an extraneous factor that can influence the relationship between two variables being studied. Specifically, for a variable to be considered a confounding variable, it needs to meet two criteria:
- It must be correlated with the independent variable (this can be causal or not)
- It must have a causal impact on the dependent variable (i.e., influence the DV)
Some common examples of confounding variables include demographic factors such as gender, ethnicity, socioeconomic status, age, education level, and health status. In addition to these, there are also environmental factors to consider. For example, air pollution could confound the impact of the variables of interest in a study investigating health outcomes.
Naturally, it’s important to identify as many confounding variables as possible when conducting your research, as they can heavily distort the results and lead you to draw incorrect conclusions . So, always think carefully about what factors may have a confounding effect on your variables of interest and try to manage these as best you can.
What is a latent variable?
Latent variables are unobservable factors that can influence the behaviour of individuals and explain certain outcomes within a study. They’re also known as hidden or underlying variables , and what makes them rather tricky is that they can’t be directly observed or measured . Instead, latent variables must be inferred from other observable data points such as responses to surveys or experiments.
For example, in a study of mental health, the variable “resilience” could be considered a latent variable. It can’t be directly measured , but it can be inferred from measures of mental health symptoms, stress, and coping mechanisms. The same applies to a lot of concepts we encounter every day – for example:
- Emotional intelligence
- Quality of life
- Business confidence
- Ease of use
One way in which we overcome the challenge of measuring the immeasurable is latent variable models (LVMs). An LVM is a type of statistical model that describes a relationship between observed variables and one or more unobserved (latent) variables. These models allow researchers to uncover patterns in their data which may not have been visible before, thanks to their complexity and interrelatedness with other variables. Those patterns can then inform hypotheses about cause-and-effect relationships among those same variables which were previously unknown prior to running the LVM. Powerful stuff, we say!

Let’s recap
In the world of scientific research, there’s no shortage of variable types, some of which have multiple names and some of which overlap with each other. In this post, we’ve covered some of the popular ones, but remember that this is not an exhaustive list .
To recap, we’ve explored:
- Independent variables (the “cause”)
- Dependent variables (the “effect”)
- Control variables (the variable that’s not allowed to vary)
If you’re still feeling a bit lost and need a helping hand with your research project, check out our 1-on-1 coaching service , where we guide you through each step of the research journey. Also, be sure to check out our free dissertation writing course and our collection of free, fully-editable chapter templates .

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...

Very informative, concise and helpful. Thank you

Helping information.Thanks

practical and well-demonstrated

Very helpful and insightful
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
Educational resources and simple solutions for your research journey

Independent vs Dependent Variables: Definitions & Examples
A variable is an important element of research. It is a characteristic, number, or quantity of any category that can be measured or counted and whose value may change with time or other parameters.
Variables are defined in different ways in different fields. For instance, in mathematics, a variable is an alphabetic character that expresses a numerical value. In algebra, a variable represents an unknown entity, mostly denoted by a, b, c, x, y, z, etc. In statistics, variables represent real-world conditions or factors. Despite the differences in definitions, in all fields, variables represent the entity that changes and help us understand how one factor may or may not influence another factor.
Variables in research and statistics are of different types—independent, dependent, quantitative (discrete or continuous), qualitative (nominal/categorical, ordinal), intervening, moderating, extraneous, confounding, control, and composite. In this article we compare the first two types— independent vs dependent variables .
Table of Contents
What is a variable?
Researchers conduct experiments to understand the cause-and-effect relationships between various entities. In such experiments, the entities whose values change are called variables. These variables describe the relationships among various factors and help in drawing conclusions in experiments. They help in understanding how some factors influence others. Some examples of variables include age, gender, race, income, weight, etc.
As mentioned earlier, different types of variables are used in research. Of these, we will compare the most common types— independent vs dependent variables . The independent variable is the cause and the dependent variable is the effect, that is, independent variables influence dependent variables. In research, a dependent variable is the outcome of interest of the study and the independent variable is the factor that may influence the outcome. Let’s explain this with an independent and dependent variable example : In a study to analyze the effect of antibiotic use on microbial resistance, antibiotic use is the independent variable and microbial resistance is the dependent variable because antibiotic use affects microbial resistance.( 1)
What is an independent variable?
Here is a list of the important characteristics of independent variables .( 2,3)
- An independent variable is the factor that is being manipulated in an experiment.
- In a research study, independent variables affect or influence dependent variables and cause them to change.
- Independent variables help gather evidence and draw conclusions about the research subject.
- They’re also called predictors, factors, treatment variables, explanatory variables, and input variables.
- On graphs, independent variables are usually placed on the X-axis.
- Example: In a study on the relationship between screen time and sleep problems, screen time is the independent variable because it influences sleep (the dependent variable).
- In addition, some factors like age are independent variables because other variables such as a person’s income will not change their age.

Types of independent variables
Independent variables in research are of the following two types:( 4)
Quantitative
Quantitative independent variables differ in amounts or scales. They are numeric and answer questions like “how many” or “how often.”
Here are a few quantitative independent variables examples :
- Differences in treatment dosages and frequencies: Useful in determining the appropriate dosage to get the desired outcome.
- Varying salinities: Useful in determining the range of salinity that organisms can tolerate.
Qualitative
Qualitative independent variables are non-numerical variables.
A few qualitative independent variables examples are listed below:
- Different strains of a species: Useful in identifying the strain of a crop that is most resistant to a specific disease.
- Varying methods of how a treatment is administered—oral or intravenous.
A quantitative variable is represented by actual amounts and a qualitative variable by categories or groups.
What is a dependent variable ?
Here are a few characteristics of dependent variables: ( 3)
- A dependent variable represents a quantity whose value depends on the independent variable and how it is changed.
- The dependent variable is influenced by the independent variable under various circumstances.
- It is also known as the response variable and outcome variable.
- On graphs, dependent variables are placed on the Y-axis.
Here are a few dependent variable examples :
- In a study on the effect of exercise on mood, the dependent variable is mood because it may change with exercise.
- In a study on the effect of pH on enzyme activity, the enzyme activity is the dependent variable because it changes with changing pH.
Types of dependent variables
Dependent variables are of two types:( 5)
Continuous dependent variables
These variables can take on any value within a given range and are measured on a continuous scale, for example, weight, height, temperature, time, distance, etc.
Categorical or discrete dependent variables
These variables are divided into distinct categories. They are not measured on a continuous scale so only a limited number of values are possible, for example, gender, race, etc.

Differences between independent and dependent variables
The following table compares independent vs dependent variables .
| How to identify | Manipulated or controlled | Observed or measured |
| Purpose | Cause or predictor variable | Outcome or response variable |
| Relationship | Independent of other variables | Influenced by the independent variable |
| Control | Manipulated or assigned by researcher | Measured or observed during experiments |
Independent and dependent variable examples
Listed below are a few examples of research questions from various disciplines and their corresponding independent and dependent variables.( 6)
| Genetics | What is the relationship between genetics and susceptibility to diseases? | genetic factors | susceptibility to diseases |
| History | How do historical events influence national identity? | historical events | national identity |
| Political science | What is the effect of political campaign advertisements on voter behavior? | political campaign advertisements | voter behavior |
| Sociology | How does social media influence cultural awareness? | social media exposure | cultural awareness |
| Economics | What is the impact of economic policies on unemployment rates? | economic policies | unemployment rates |
| Literature | How does literary criticism affect book sales? | literary criticism | book sales |
| Geology | How do a region’s geological features influence the magnitude of earthquakes? | geological features | earthquake magnitudes |
| Environment | How do changes in climate affect wildlife migration patterns? | climate changes | wildlife migration patterns |
| Gender studies | What is the effect of gender bias in the workplace on job satisfaction? | gender bias | job satisfaction |
| Film studies | What is the relationship between cinematographic techniques and viewer engagement? | cinematographic techniques | viewer engagement |
| Archaeology | How does archaeological tourism affect local communities? | archaeological techniques | local community development |
Independent vs dependent variables in research
Experiments usually have at least two variables—independent and dependent. The independent variable is the entity that is being tested and the dependent variable is the result. Classifying independent and dependent variables as discrete and continuous can help in determining the type of analysis that is appropriate in any given research experiment, as shown in the table below. ( 7)
| Chi-Square | t-test | ||
| Logistic regression | ANOVA | ||
| Phi | Regression | ||
| Cramer’s V | Point-biserial correlation | ||
| Logistic regression | Regression | ||
| Point-biserial correlation | Correlation | ||
Here are some more research questions and their corresponding independent and dependent variables. ( 6)
| What is the impact of online learning platforms on academic performance? | type of learning | academic performance |
| What is the association between exercise frequency and mental health? | exercise frequency | mental health |
| How does smartphone use affect productivity? | smartphone use | productivity levels |
| Does family structure influence adolescent behavior? | family structure | adolescent behavior |
| What is the impact of nonverbal communication on job interviews? | nonverbal communication | job interviews |
How to identify independent vs dependent variables
In addition to all the characteristics of independent and dependent variables listed previously, here are few simple steps to identify the variable types in a research question.( 8)
- Keep in mind that there are no specific words that will always describe dependent and independent variables.
- If you’re given a paragraph, convert that into a question and identify specific words describing cause and effect.
- The word representing the cause is the independent variable and that describing the effect is the dependent variable.
Let’s try out these steps with an example.
A researcher wants to conduct a study to see if his new weight loss medication performs better than two bestseller alternatives. He wants to randomly select 20 subjects from Richmond, Virginia, aged 20 to 30 years and weighing above 60 pounds. Each subject will be randomly assigned to three treatment groups.
To identify the independent and dependent variables, we convert this paragraph into a question, as follows: Does the new medication perform better than the alternatives? Here, the medications are the independent variable and their performances or effect on the individuals are the dependent variable.

Visualizing independent vs dependent variables
Data visualization is the graphical representation of information by using charts, graphs, and maps. Visualizations help in making data more understandable by making it easier to compare elements, identify trends and relationships (among variables), among other functions.
Bar graphs, pie charts, and scatter plots are the best methods to graphically represent variables. While pie charts and bar graphs are suitable for depicting categorical data, scatter plots are appropriate for quantitative data. The independent variable is usually placed on the X-axis and the dependent variable on the Y-axis.
Figure 1 is a scatter plot that depicts the relationship between the number of household members and their monthly grocery expenses. 9 The number of household members is the independent variable and the expenses the dependent variable. The graph shows that as the number of members increases the expenditure also increases.

Key takeaways
Let’s summarize the key takeaways about independent vs dependent variables from this article:
- A variable is any entity being measured in a study.
- A dependent variable is often the focus of a research study and is the response or outcome. It depends on or varies with changes in other variables.
- Independent variables cause changes in dependent variables and don’t depend on other variables.
- An independent variable can influence a dependent variable, but a dependent variable cannot influence an independent variable.
- An independent variable is the cause and dependent variable is the effect.
Frequently asked questions
- What are the different types of variables used in research?
The following table lists the different types of variables used in research.( 10)
| Categorical | Measures a construct that has different categories | gender, race, religious affiliation, political affiliation |
| Quantitative | Measures constructs that vary by degree of the amount | weight, height, age, intelligence scores |
| Independent (IV) | Measures constructs considered to be the cause | Higher education (IV) leads to higher income (DV) |
| Dependent (DV) | Measures constructs that are considered the effect | Exercise (IV) will reduce anxiety levels (DV) |
| Intervening or mediating (MV) | Measures constructs that intervene or stand in between the cause and effect | Incarcerated individuals are more likely to have psychiatric disorder (MV), which leads to disability in social roles |
| Confounding (CV) | “Rival explanations” that explain the cause-and-effect relationship | Age (CV) explains the relationship between increased shoe size and increase in intelligence in children |
| Control variable | Extraneous variables whose influence can be controlled or eliminated | Demographic data such as gender, socioeconomic status, age |
2. Why is it important to differentiate between independent vs dependent variables ?
Differentiating between independent vs dependent variables is important to ensure the correct application in your own research and also the correct understanding of other studies. An incorrectly framed research question can lead to confusion and inaccurate results. An easy way to differentiate is to identify the cause and effect.
3. How are independent and dependent variables used in non-experimental research?
So far in this article we talked about variables in relation to experimental research, wherein variables are manipulated or measured to test a hypothesis, that is, to observe the effect on dependent variables. Let’s examine non-experimental research and how variable are used. 11 In non-experimental research, variables are not manipulated but are observed in their natural state. Researchers do not have control over the variables and cannot manipulate them based on their research requirements. For example, a study examining the relationship between income and education level would not manipulate either variable. Instead, the researcher would observe and measure the levels of each variable in the sample population. The level of control researchers have is the major difference between experimental and non-experimental research. Another difference is the causal relationship between the variables. In non-experimental research, it is not possible to establish a causal relationship because other variables may be influencing the outcome.
4. Are there any advantages and disadvantages of using independent vs dependent variables ?
Here are a few advantages and disadvantages of both independent and dependent variables.( 12)
Advantages:
- Dependent variables are not liable to any form of bias because they cannot be manipulated by researchers or other external factors.
- Independent variables are easily obtainable and don’t require complex mathematical procedures to be observed, like dependent variables. This is because researchers can easily manipulate these variables or collect the data from respondents.
- Some independent variables are natural factors and cannot be manipulated. They are also easily obtainable because less time is required for data collection.
Disadvantages:
- Obtaining dependent variables is a very expensive and effort- and time-intensive process because these variables are obtained from longitudinal research by solving complex equations.
- Independent variables are prone to researcher and respondent bias because they can be manipulated, and this may affect the study results.
We hope this article has provided you with an insight into the use and importance of independent vs dependent variables , which can help you effectively use variables in your next research study.
- Kaliyadan F, Kulkarni V. Types of variables, descriptive statistics, and sample size. Indian Dermatol Online J. 2019 Jan-Feb; 10(1): 82–86. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6362742/
- What Is an independent variable? (with uses and examples). Indeed website. Accessed March 11, 2024. https://www.indeed.com/career-advice/career-development/what-is-independent-variable
- Independent and dependent variables: Differences & examples. Statistics by Jim website. Accessed March 10, 2024. https://statisticsbyjim.com/regression/independent-dependent-variables/
- Independent variable. Biology online website. Accessed March 9, 2024. https://www.biologyonline.com/dictionary/independent-variable#:~:text=The%20independent%20variable%20in%20research,how%20many%20or%20how%20often .
- Dependent variables: Definition and examples. Clubz Tutoring Services website. Accessed March 10, 2024. https://clubztutoring.com/ed-resources/math/dependent-variable-definitions-examples-6-7-2/
- Research topics with independent and dependent variables. Good research topics website. Accessed March 12, 2024. https://goodresearchtopics.com/research-topics-with-independent-and-dependent-variables/
- Levels of measurement and using the correct statistical test. Univariate quantitative methods. Accessed March 14, 2024. https://web.pdx.edu/~newsomj/uvclass/ho_levels.pdf
- Easiest way to identify dependent and independent variables. Afidated website. Accessed March 15, 2024. https://www.afidated.com/2014/07/how-to-identify-dependent-and.html
- Choosing data visualizations. Math for the people website. Accessed March 14, 2024. https://web.stevenson.edu/mbranson/m4tp/version1/environmental-racism-choosing-data-visualization.html
- Trivedi C. Types of variables in scientific research. Concepts Hacked website. Accessed March 15, 2024. https://conceptshacked.com/variables-in-scientific-research/
- Variables in experimental and non-experimental research. Statistics solutions website. Accessed March 14, 2024. https://www.statisticssolutions.com/variables-in-experimental-and-non-experimental-research/#:~:text=The%20independent%20variable%20would%20be,state%20instead%20of%20manipulating%20them .
- Dependent vs independent variables: 11 key differences. Formplus website. Accessed March 15, 2024. https://www.formpl.us/blog/dependent-independent-variables
Editage All Access is a subscription-based platform that unifies the best AI tools and services designed to speed up, simplify, and streamline every step of a researcher’s journey. The Editage All Access Pack is a one-of-a-kind subscription that unlocks full access to an AI writing assistant, literature recommender, journal finder, scientific illustration tool, and exclusive discounts on professional publication services from Editage.
Based on 22+ years of experience in academia, Editage All Access empowers researchers to put their best research forward and move closer to success. Explore our top AI Tools pack, AI Tools + Publication Services pack, or Build Your Own Plan. Find everything a researcher needs to succeed, all in one place – Get All Access now starting at just $14 a month !
Related Posts

Back to School – Lock-in All Access Pack for a Year at the Best Price

Journal Turnaround Time: Researcher.Life and Scholarly Intelligence Join Hands to Empower Researchers with Publication Time Insights
Variables in Quantitative Research: A Beginner's Guide – SOBT
Quantitative variables.
Because quantitative methodology requires measurement, the concepts being investigated need to be defined in a way that can be measured. Organizational change, reading comprehension, emergency response, or depression are concepts but they cannot be measured as such. Frequency of organizational change, reading comprehension scores, emergency response time, or types of depression can be measured. They are variables (concepts that can vary).
Quantitative research involves many kinds of variables. There are four main types:
- Independent variables (IV).
- Dependent variables (DV).
- Sample variables.
- Extraneous variables.
Each is discussed below.
Independent Variables (IV)
Independent variables (IV) are those that are suspected of being the cause in a causal relationship. If you are asking a cause and effect question, your IV will be the variable (or variables if more than one) that you suspect causes the effect.
There are two main sorts of IV, active independent variables and attribute independent variables:
- Active IV are interventions or conditions that are being applied to the participants. A special tutorial for the third graders, a new therapy for clients, or a new training program being tested on employees would be active IVs.
- Attribute IV are intrinsic characteristics of the participants that are suspected of causing a result. For example, if you are examining whether gender—which is intrinsic to the participants—results in higher or lower scores on some skill, gender is an attribute IV.
- Both types of IV can have what are called levels. For example:
- In the example above, the active IV special tutorial , receiving the tutorial is one level, and tutorial withheld (control) is a second level.
- In the same example, being a third grader would be an attribute IV. It could be defined as only one level—being in third grade—or you might wish to define it with more than one level, such as first half of third grade and second half of third grade. Indeed, that attribute IV could take many more, for example, if you wished to look at each month of third grade.
Independent variables are frequently called different things depending on the nature of the research question. In predictive questions where a variable is thought to predict another but it is not yet appropriate to ask whether it causes the other, the IV is usually called a predictor or criterion variable rather than an independent variable.
Dependent Variables (DV)
Dependent variables are those that are influenced by the independent variables. If you ask,"Does A cause [or predict or influence or affect, and so on] B?," then B is the dependent variable (DV).
- Dependent variables are variables that depend on or are influenced by the independent variables.
- They are outcomes or results of the influence of the independent variable.
- Dependent variables answer the question: What do I observe happening when I apply the intervention?
- The dependent variable receives the intervention.
In questions where full causation is not assumed, such as a predictive question or a question about differences between groups but no manipulation of an IV, the dependent variables are usually called outcome variables , and the independent variables are usually called the predictor or criterion variables.
Sample Variables
In some studies, some characteristic of the participants must be measured for some reason, but that characteristic is not the IV or the DV. In this case, these are called sample variables. For example, suppose you are investigating whether servant leadership style affects organizational performance and successful financial outcomes. In order to obtain a sample of servant leaders, a standard test of leadership style will be administered. So the presence or absence of servant leadership style will be a sample variable. That score is not used as an IV or a DV, but simply to get the appropriate people into the sample.
When there is no measure of a characteristic of the participants, the characteristic is called a "sample characteristic." When the characteristic must be measured, it is called a "sample variable."
Extraneous Variables
Extraneous variables are not of interest to the study but may influence the dependent variable. For this reason, most quantitative studies attempt to control extraneous variables. The literature should inform you what extraneous variables to account for.
There is a special class of extraneous variables called confounding variables. These are variables that can cause the effect we are looking for if they are not controlled for, resulting in a false finding that the IV is effective when it is not. In a study of changes in skill levels in a group of workers after a training program, if the follow-up measure is taken relatively late after the training, the simple effect of practicing the skills might explain improved scores, and the training might be mistakenly thought to be successful when it was not.
There are many details about variables not covered in this handout. Please consult any text on research methods for a more comprehensive review.
Doc. reference: phd_t2_sobt_u02s2_h01_quantvar.html.html
Independent and Dependent Variables
This guide discusses how to identify independent and dependent variables effectively and incorporate their description within the body of a research paper.
A variable can be anything you might aim to measure in your study, whether in the form of numerical data or reflecting complex phenomena such as feelings or reactions. Dependent variables change due to the other factors measured, especially if a study employs an experimental or semi-experimental design. Independent variables are stable: they are both presumed causes and conditions in the environment or milieu being manipulated.
Identifying Independent and Dependent Variables
Even though the definitions of the terms independent and dependent variables may appear to be clear, in the process of analyzing data resulting from actual research, identifying the variables properly might be challenging. Here is a simple rule that you can apply at all times: the independent variable is what a researcher changes, whereas the dependent variable is affected by these changes. To illustrate the difference, a number of examples are provided below.
- The purpose of Study 1 is to measure the impact of different plant fertilizers on how many fruits apple trees bear. Independent variable : plant fertilizers (chosen by researchers) Dependent variable : fruits that the trees bear (affected by choice of fertilizers)
- The purpose of Study 2 is to find an association between living in close vicinity to hydraulic fracturing sites and respiratory diseases. Independent variable: proximity to hydraulic fracturing sites (a presumed cause and a condition of the environment) Dependent variable: the percentage/ likelihood of suffering from respiratory diseases
Confusion is possible in identifying independent and dependent variables in the social sciences. When considering psychological phenomena and human behavior, it can be difficult to distinguish between cause and effect. For example, the purpose of Study 3 is to establish how tactics for coping with stress are linked to the level of stress-resilience in college students. Even though it is feasible to speculate that these variables are interdependent, the following factors should be taken into account in order to clearly define which variable is dependent and which is interdependent.
- The dependent variable is usually the objective of the research. In the study under examination, the levels of stress resilience are being investigated.
- The independent variable precedes the dependent variable. The chosen stress-related coping techniques help to build resilience; thus, they occur earlier.
Writing Style and Structure
Usually, the variables are first described in the introduction of a research paper and then in the method section. No strict guidelines for approaching the subject exist; however, academic writing demands that the researcher make clear and concise statements. It is only reasonable not to leave readers guessing which of the variables is dependent and which is independent. The description should reflect the literature review, where both types of variables are identified in the context of the previous research. For instance, in the case of Study 3, a researcher would have to provide an explanation as to the meaning of stress resilience and coping tactics.
In properly organizing a research paper, it is essential to outline and operationalize the appropriate independent and dependent variables. Moreover, the paper should differentiate clearly between independent and dependent variables. Finding the dependent variable is typically the objective of a study, whereas independent variables reflect influencing factors that can be manipulated. Distinguishing between the two types of variables in social sciences may be somewhat challenging as it can be easy to confuse cause with effect. Academic format calls for the author to mention the variables in the introduction and then provide a detailed description in the method section.
Unfortunately, your browser is too old to work on this site.
For full functionality of this site it is necessary to enable JavaScript.
- Thesis Action Plan New
- Academic Project Planner
Literature Navigator
Thesis dialogue blueprint, writing wizard's template, research proposal compass.
- Why students love us
- Rebels Blog
- Why we are different
- All Products
- Coming Soon
Operationalize a Variable: A Step-by-Step Guide to Quantifying Your Research Constructs

Operationalizing a variable is a fundamental step in transforming abstract research constructs into measurable entities. This process allows researchers to quantify variables, enabling the empirical testing of hypotheses within quantitative research. The guide provided here aims to demystify the operationalization process with a structured approach, equipping scholars with the tools to translate theoretical concepts into practical, quantifiable measures.
Key Takeaways
- Operationalization is crucial for converting theoretical constructs into measurable variables, forming the backbone of empirical research.
- Identifying the right variables involves distinguishing between constructs and variables, and selecting those that align with the research objectives.
- The validity and reliability of measurements are ensured by choosing appropriate measurement instruments and calibrating them for consistency.
- Quantitative analysis of qualitative data requires careful operationalization to maintain the integrity and applicability of research findings.
- Operationalization impacts research outcomes by influencing study validity, generalizability, and contributing to the academic field's advancement.
Understanding the Concept of Operationalization in Research
Defining operationalization.
Operationalization is the cornerstone of quantitative research, transforming abstract concepts into measurable entities. It is the process by which you translate theoretical constructs into variables that can be empirically measured. This crucial step allows you to quantify the phenomena of interest, paving the way for systematic investigation and analysis.
To operationalize a variable effectively, you must first clearly define the construct and then determine the specific ways in which it can be observed and quantified. For instance, if you're studying the concept of 'anxiety,' you might operationalize it by measuring heart rate, self-reported stress levels, or the frequency of anxiety-related behaviors.
Consider the following aspects when operationalizing your variables:
- The type of variable (e.g., binary, continuous, categorical)
- The units of measurement (e.g., dollars, frequency, Likert scale)
- The method of data collection (e.g., surveys, observations, physiological measures)
By meticulously defining and measuring your variables, you ensure that your research can be rigorously tested and validated, contributing to the robustness and credibility of your findings.
The Role of Operationalization in Quantitative Research
In quantitative research, operationalization is the cornerstone that bridges the gap between abstract concepts and measurable outcomes. It involves defining your research variables in practical, quantifiable terms, allowing for precise data collection and analysis. Operationalization transforms theoretical constructs into indicators that can be empirically tested , ensuring that your study can be objectively evaluated against your hypotheses.
Operationalization is not just about measurement, but about the meaning behind the numbers. It requires careful consideration to select the most appropriate indicators for your variables. For instance, if you're studying educational achievement, you might operationalize this as GPA, standardized test scores, or graduation rates. Each choice has implications for what aspect of 'achievement' you're measuring:
- GPA reflects consistent performance across a variety of subjects.
- Standardized test scores may indicate aptitude in specific areas.
- Graduation rates can signify the completion of an educational milestone.
By operationalizing variables effectively, you lay the groundwork for a robust quantitative study. This process ensures that your research can be replicated and that your findings contribute meaningfully to the existing body of knowledge.
Differences Between Endogenous and Exogenous Variables
In the realm of research, understanding the distinction between endogenous and exogenous variables is crucial for designing robust experiments and drawing accurate conclusions. Endogenous variables are those that are influenced within the context of the study, often affected by other variables in the system. In contrast, exogenous variables are external factors that are not influenced by the system under study but can affect endogenous variables.
When operationalizing variables, it is essential to identify which are endogenous and which are exogenous to establish clear causal relationships. Exogenous variables are typically manipulated to observe their effect on endogenous variables, thereby testing hypotheses about causal links. For example, in a study on education outcomes, student motivation might be an endogenous variable, while teaching methods could be an exogenous variable manipulated by the researcher.
Consider the following points to differentiate between these two types of variables:
- Endogenous variables are outcomes within the system, subject to influence by other variables.
- Exogenous variables serve as inputs or causes that can be controlled or manipulated.
- The operationalization of endogenous variables requires careful consideration of how they are measured and how they interact with other variables.
- Exogenous variables, while not requiring operationalization, must be selected with an understanding of their potential impact on the system.
Identifying Variables for Operationalization
Distinguishing between variables and constructs.
In the realm of research, it's crucial to differentiate between variables and constructs. A variable is a specific, measurable characteristic that can vary among participants or over time. Constructs, on the other hand, are abstract concepts that are not directly observable and must be operationalized into measurable variables. For example, intelligence is a construct that can be operationalized by measuring IQ scores, which are variables.
Variables can be classified into different types , each with its own method of measurement. Here's a brief overview of these types:
- Continuous: Can take on any value within a range (e.g., height, weight).
- Ordinal: Represent order without specifying the magnitude of difference (e.g., socioeconomic status levels).
- Nominal: Categories without a specific order (e.g., types of fruit).
- Binary: Two categories, often representing presence or absence (e.g., employed/unemployed).
- Count: The number of occurrences (e.g., number of visits to a website).
When you embark on your research journey, ensure that you clearly identify each construct and the corresponding variable that will represent it in your study. This clarity is the foundation for a robust and credible research design.
Criteria for Selecting Variables
When you embark on the journey of operationalizing variables for your research, it is crucial to apply a systematic approach to variable selection. Variables should be chosen based on their relevance to your research questions and hypotheses , ensuring that they directly contribute to the investigation of your theoretical constructs.
Consider the type of variable you are dealing with—whether it is continuous, ordinal, nominal, binary, or count. Each type has its own implications for how data will be collected and analyzed. For instance, continuous variables allow for a wide range of values, while binary variables are restricted to two possible outcomes. Here is a brief overview of variable types and their characteristics:
- Continuous : Can take on any value within a range
- Ordinal : Values have a meaningful order but intervals are not necessarily equal
- Nominal : Categories without a meaningful order
- Binary : Only two possible outcomes
- Count : Integer values that represent the number of occurrences
Additionally, ensure that the levels of the variable encompass all possible values and that these levels are clearly defined. For binary and ordinal variables, this means specifying the two outcomes or the order of values, respectively. For continuous variables, define the range and consider using categories like 'above X' or 'below Y' if there are no natural bounds to the values.
Lastly, the proxy attribute of the variable should be considered. This refers to the induced variations or treatment conditions in your experiment. For example, if you are studying the effect of a buyer's budget on purchasing decisions, the proxy attribute might include different budget levels such as $5, $10, $20, and $40.
Developing Hypotheses and Research Questions
After grasping the fundamentals of your research domain, the next pivotal step is to develop a clear and concise hypothesis. This hypothesis will serve as the foundation for your experimental design and guide the direction of your study. Formulating a hypothesis requires a deep understanding of the variables at play and their potential interrelations . It's essential to ensure that your hypothesis is testable and that you have a structured plan for how to test it.
Once your hypothesis is established, you'll need to craft research questions that are both specific and measurable. These questions should stem directly from your hypothesis and aim to dissect the larger inquiry into more manageable segments. Here's how to find research question: start by identifying key outcomes and potential causes that might affect these outcomes. Then, design an experiment to induce variation in the causes and measure the outcomes. Remember, the clarity of your research questions will significantly impact the effectiveness of your data analysis later on.
To aid in this process, consider the following steps:
- Synthesize the existing literature to identify gaps and opportunities for further investigation.
- Define a clear problem statement that your research will address.
- Establish a purpose statement that guides your inquiry without advocating for a specific outcome.
- Develop a conceptual and theoretical framework to underpin your research.
- Formulate quantitative and qualitative research questions that align with your hypothesis and frameworks.
Effective experimental design involves identifying variables, establishing hypotheses, choosing sample size, and implementing randomization and control groups to ensure reliable and meaningful research results.
Choosing the Right Measurement Instruments
Types of measurement instruments.
When you embark on the journey of operationalizing your variables, selecting the right measurement instruments is crucial. These instruments are the tools that will translate your theoretical constructs into observable and measurable data. Understanding the different types of measurement instruments is essential for ensuring that your data accurately reflects the constructs you are studying.
Measurement instruments can be broadly categorized into five types: continuous, ordinal, nominal, binary, and count. Each type is suited to different kinds of data and research questions. For instance, a continuous variable, like height, can take on any value within a range, while an ordinal variable represents ordered categories, such as a satisfaction scale.
Here is a brief overview of the types of measurement instruments:
- Continuous : Can take on any value within a range; e.g., temperature, weight.
- Ordinal : Represents ordered categories; e.g., Likert scales for surveys.
- Nominal : Categorizes data without a natural order; e.g., types of fruit, gender.
- Binary : Has only two categories; e.g., yes/no questions, presence/absence.
- Count : Represents the number of occurrences; e.g., the number of visits to a website.
Choosing the appropriate instrument involves considering the nature of your variable, the level of detail required, and the context of your research. For example, if you are measuring satisfaction levels, you might use a Likert scale, which is an ordinal type of instrument. On the other hand, if you are counting the number of times a behavior occurs, a count instrument would be more appropriate.
Ensuring Validity and Reliability
To ensure the integrity of your research, it is crucial to select measurement instruments that are both valid and reliable. Validity refers to the degree to which an instrument accurately measures what it is intended to measure. Reliability, on the other hand, denotes the consistency of the instrument across different instances of measurement.
When choosing your instruments, consider the psychometric properties that have been documented in large cohort studies or previous validations. For instance, scales should have demonstrated internal consistency reliability, which can be assessed using statistical measures such as Cronbach's alpha. It is also important to calibrate your instruments to maintain consistency over time and across various contexts.
Here is a simplified checklist to guide you through the process:
- Review literature for previously validated instruments
- Check for cultural and linguistic validation if applicable
- Assess internal consistency reliability (e.g., Cronbach's alpha)
- Perform pilot testing and calibration
- Plan for ongoing assessment of instrument performance
Calibrating Instruments for Consistency
Calibration is a critical step in ensuring that your measurement instruments yield reliable and consistent results. It involves adjusting the instrument to align with a known standard or set of standards. Calibration must be performed periodically to maintain the integrity of data collection over time.
When calibrating instruments, you should follow a systematic approach. Here is a simple list to guide you through the process:
- Identify the standard against which the instrument will be calibrated.
- Compare the instrument's output with the standard.
- Adjust the instrument to minimize any discrepancies.
- Document the calibration process and results for future reference.
It's essential to recognize that different instruments may require unique calibration methods. For instance, a scale used for measuring weight will be calibrated differently than a thermometer used for temperature. Below is an example of how calibration data might be recorded in a table format:
| Instrument | Standard Used | Pre-Calibration Reading | Post-Calibration Adjustment | Date of Calibration |
|---|---|---|---|---|
| Scale | 1 kg Weight | 1.02 kg | -0.02 kg | 2023-04-15 |
| Thermometer | 0°C Ice Bath | 0.5°C | -0.5°C | 2023-04-15 |
Remember, the goal of calibration is not just to adjust the instrument but to understand its behavior and limitations. This understanding is crucial for interpreting the data accurately and ensuring that your research findings are robust and reliable.
Quantifying Variables: From Theory to Practice
Translating theoretical constructs into measurable variables.
Operationalizing a variable is the cornerstone of empirical research, transforming abstract concepts into quantifiable measures. Your ability to effectively operationalize variables is crucial for testing hypotheses and advancing knowledge within your field. Begin by identifying the key constructs of your study and consider how they can be observed in the real world.
For instance, if your research involves the construct of 'anxiety,' you must decide on a method to measure it. Will you use a self-reported questionnaire, physiological indicators, or a combination of both? Each method has implications for the type of data you will collect and how you will interpret it. Below is an example of how you might structure this information:
- Construct: Anxiety
- Measurement Method: Self-reported questionnaire
- Instrument: Beck Anxiety Inventory
- Scale: 0 (no anxiety) to 63 (severe anxiety)
Once you have chosen an appropriate measurement method, ensure that it aligns with your research objectives and provides valid and reliable data. This process may involve adapting existing instruments or developing new ones to suit the specific needs of your study. Remember, the operationalization of your variables sets the stage for the empirical testing of your theoretical framework.
Assigning Units and Scales of Measurement
Once you have translated your theoretical constructs into measurable variables, the next critical step is to assign appropriate units and scales of measurement. Units are the standards used to quantify the value of your variables, ensuring consistency and robustness in your data. For instance, if you are measuring time spent on a task, your unit might be minutes or seconds.
Variables can be categorized into types such as continuous, ordinal, nominal, binary, or count. This classification aids in selecting the right scale of measurement and is crucial for the subsequent statistical analysis. For example, a continuous variable like height would be measured in units such as centimeters or inches, while an ordinal variable like satisfaction level might be measured on a Likert scale ranging from 'Very Dissatisfied' to 'Very Satisfied'.
Here is a simple table illustrating different variable types and their potential units or scales:
| Variable Type | Example | Unit/Scale |
|---|---|---|
| Continuous | Height | Centimeters (cm) |
| Ordinal | Satisfaction Level | Likert Scale (1-5) |
| Nominal | Blood Type | A, B, AB, O |
| Binary | Gender | Male (1), Female (0) |
| Count | Number of Visits | Count (number of visits) |
Remember, the choice of units and scales will directly impact the validity of your research findings. It is essential to align them with your research objectives and the nature of the data you intend to collect.
Handling Qualitative Data in Quantitative Analysis
When you embark on the journey of operationalizing variables, you may encounter the challenge of incorporating qualitative data into a quantitative framework. Operationalization is the process of translating abstract concepts into measurable variables in research, which is crucial for ensuring the study's validity and reliability. However, qualitative data, with its rich, descriptive nature, does not lend itself easily to numerical representation.
To effectively handle qualitative data, you must first systematically categorize the information. This can be done through coding, where themes, patterns, and categories are identified. Once coded, these qualitative elements can be quantified. For example, the frequency of certain themes can be counted, or the presence of specific categories can be used as binary variables (0 for absence, 1 for presence).
Consider the following table that illustrates a simple coding scheme for qualitative responses:
| Theme | Code | Frequency |
|---|---|---|
| Satisfaction | 1 | 45 |
| Improvement Needed | 2 | 30 |
| No Opinion | 3 | 25 |
This table represents a basic way to transform qualitative feedback into quantifiable data, which can then be analyzed using statistical methods. It is essential to ensure that the coding process is consistent and that the interpretation of qualitative data remains faithful to the original context. By doing so, you can enrich your quantitative analysis with the depth that qualitative insights provide, while maintaining the rigor of a quantitative approach.
Designing the Experimental Framework
Creating a structured causal model (scm).
In your research, constructing a Structured Causal Model (SCM) is a pivotal step that translates your theoretical understanding into a practical framework. SCMs articulate the causal relationships between variables through a set of equations or functions, allowing you to make clear and testable hypotheses about the phenomena under study. By defining these relationships explicitly, SCMs facilitate the prediction and manipulation of outcomes in a controlled experimental setting.
When developing an SCM, consider the following steps:
- Identify the key variables and their hypothesized causal connections.
- Choose the appropriate mathematical representation for each relationship (e.g., linear, logistic).
- Determine the directionality of the causal effects.
- Specify any interaction terms or non-linear dynamics that may be present.
- Validate the SCM by ensuring it aligns with existing theoretical and empirical evidence.
Remember, the SCM is not merely a statistical tool; it embodies your hypotheses about the causal structure of your research question. As such, it should be grounded in theory and prior research, while also being amenable to empirical testing. The SCM approach circumvents the need to search for causal structures post hoc, as it requires you to specify the causal framework a priori, thus avoiding common pitfalls such as 'bad controls' and ensuring that exogenous variation is properly accounted for.
Determining the Directionality of Variables
In the process of operationalizing variables, understanding the directionality is crucial. Directed acyclic graphs (DAGs) serve as a fundamental tool in delineating causal relationships between variables. The direction of the arrow in a DAG explicitly indicates the causal flow, which is essential for constructing a valid Structural Causal Model (SCM).
When you classify variables, you must consider their types —continuous, ordinal, nominal, binary, or count. This classification not only aids in understanding the variables' nature but also in selecting the appropriate statistical methods for analysis. Here is a simple representation of variable types and their characteristics:
| Variable Type | Description |
|---|---|
| Continuous | Can take any value within a range |
| Ordinal | Ranked order without fixed intervals |
| Nominal | Categories without a natural order |
| Binary | Two categories, often 0 and 1 |
| Count | Non-negative integer values |
By integrating the directionality and type of variables into your research design, you ensure that the operationalization is aligned with the underlying theoretical framework. This alignment is pivotal for the subsequent phases of data collection and analysis, ultimately impacting the robustness of your research findings.
Pre-Analysis Planning and Experimental Design
As you embark on the journey of experimental design, it's crucial to have a clear pre-analysis plan. This plan will guide you through the data collection process and ensure that your analysis is aligned with your research objectives. Developing a pre-analysis plan is akin to creating a roadmap for your research , providing direction and structure to the analytical phase of your study.
To mitigate thesis anxiety , a structured approach to experimental design is essential. Begin by identifying your main research questions and hypotheses. Then, delineate the methods you'll use to test these hypotheses, including the statistical models and the criteria for interpreting results. Here's a simplified checklist to help you organize your pre-analysis planning:
- Define the research questions and hypotheses
- Select the statistical methods for analysis
- Establish criteria for interpreting the results
- Plan for potential contingencies and alternative scenarios
Remember, the robustness of your findings hinges on the meticulousness of your experimental design. By adhering to a well-thought-out pre-analysis plan, you not only enhance the credibility of your research but also pave the way for a smoother, more confident research experience.
Data Collection Strategies
Selecting appropriate data collection methods.
When you embark on the journey of research, selecting the right data collection methods is pivotal to the integrity of your study. It's essential to identify the research method as qualitative, quantitative, or mixed, and provide a clear overview of how the study will be conducted. This includes detailing the instruments or methods you will use, the subjects involved, and the setting of your research.
To ensure that your findings are reliable and valid, it is crucial to modify the data collection process , refine variables, and implement controls. This is where understanding how to find literature on existing methods can be invaluable. Literature reviews help you evaluate scientific literature for measures with strong psychometric properties and use cases relevant to your study. Consider the following steps to guide your selection process:
- Review criteria and priorities for construct selection.
- Evaluate relevant scientific literature for established measures.
- Examine measures used in large epidemiologic studies for alignment opportunities.
- Coordinate internally to avoid duplication and ensure comprehensive coverage.
By meticulously selecting data collection methods that align with your research objectives and hypotheses, you lay the groundwork for insightful and impactful research findings.
Sampling Techniques and Population Considerations
When you embark on the journey of research, selecting the appropriate sampling techniques is crucial to the integrity of your study. Sampling enables you to focus on a smaller subset of participants, which is a practical approach to studying larger populations. It's essential to consider the balance between a sample that is both representative of the population and manageable in size.
To ensure that your sample accurately reflects the population, you must be meticulous in your selection process. Various sampling methods are available, each with its own advantages and disadvantages. For instance, random sampling can help eliminate bias, whereas stratified sampling ensures specific subgroups are represented. Below is a list of common sampling techniques and their primary characteristics:
- Random Sampling : Each member of the population has an equal chance of being selected.
- Stratified Sampling : The population is divided into subgroups, and random samples are taken from each.
- Cluster Sampling : The population is divided into clusters, and a random sample of clusters is studied.
- Convenience Sampling : Participants are selected based on their availability and willingness to take part.
- Snowball Sampling : Existing study subjects recruit future subjects from among their acquaintances.
Remember, the choice of sampling method will impact the generalizability of your findings. It's imperative to align your sampling strategy with your research questions and the practical constraints of your study.
Ethical Considerations in Data Collection
When you embark on data collection, ethical considerations must be at the forefront of your planning. Ensuring the privacy and confidentiality of participants is paramount. You must obtain informed consent, which involves clearly communicating the purpose of your research, the procedures involved, and any potential risks or benefits to the participants.
Consider the following points to uphold ethical standards:
- Respect for anonymity and confidentiality
- Voluntary participation with the right to withdraw at any time
- Minimization of any potential harm or discomfort
- Equitable selection of participants
It is also essential to consider the sensitivity of the information you are collecting and the context in which it is gathered. For instance, when dealing with vulnerable populations or sensitive topics, additional safeguards should be in place to protect participant welfare. Lastly, ensure that your data collection methods comply with all relevant laws and institutional guidelines.
Analyzing and Interpreting Quantified Data
Statistical analysis techniques.
Once you have collected your data, it's time to analyze it using appropriate statistical techniques. The choice of analysis method depends on the nature of your data and the research questions you aim to answer. For instance, if you're looking to understand relationships between variables, regression analysis might be the method of choice. Choosing the right statistical method is crucial as it influences the validity of your research findings.
Several software packages can aid in this process, such as SPSS, R, or Python libraries like 'pandas' and 'numpy' for data manipulation, and 'pingouin' or 'stats' for statistical testing. Each package has its strengths, and your selection should align with your research needs and proficiency level.
To illustrate, consider the following table summarizing different statistical tests and their typical applications:
| Statistical Test | Application Scenario |
|---|---|
| T-test | Comparing means between two groups |
| ANOVA | Comparing means across multiple groups |
| Chi-square test | Testing relationships between categorical variables |
| Regression analysis | Exploring relationships between and independent variables |
After conducting the appropriate analyses, interpreting the results is your next step. This involves understanding the statistical significance, effect sizes, and confidence intervals to draw meaningful conclusions about your research hypotheses.
Understanding the Implications of Data
Once you have quantified your research variables, the next critical step is to understand the implications of the data you've collected. Interpreting the data correctly is crucial for drawing meaningful conclusions that align with your research objectives. It's essential to recognize that data does not exist in a vacuum; it is influenced by the context in which it was gathered. For instance, quantitative data in the form of surveys, polls, and questionnaires can yield precise results, but these must be considered within the broader social and environmental context to avoid misleading interpretations.
The process of data analysis often reveals patterns and relationships that were not initially apparent. However, caution is advised when inferring causality from these findings. The presence of a correlation does not imply causation, and additional analysis is required to establish causal links. Below is a simplified example of how data might be presented and the initial observations that could be drawn:
| Variable A | Variable B | Correlation Coefficient |
|---|---|---|
| 5 | 20 | 0.85 |
| 15 | 35 | 0.75 |
| 25 | 50 | 0.65 |
In this table, a strong positive correlation is observed between Variable A and Variable B, suggesting a potential relationship worth further investigation. Finally, the interpretation of data should always be done with an awareness of its limitations and the potential for different conclusions when analyzing it independently. This understanding is vital for ensuring that your research findings are robust, reliable, and ultimately, valuable to the field of study.
Reporting Findings with Precision
When you report the findings of your research, precision is paramount. Ensure that your data is presented clearly , with all necessary details to support your conclusions. This includes specifying the statistical methods used, such as regression analysis, and the outcomes derived from these methods. For example, when reporting statistical results, it's common to include measures like mean, standard deviation (SD), range, median, and interquartile range (IQR).
Consider the following table as a succinct way to present your data:
| Measure | Value |
|---|---|
| Mean | X |
| SD | Y |
| Range | Z |
| Median | A |
| IQR | B |
In addition to numerical data, provide a narrative that contextualizes your findings within the broader scope of your research. Discuss any potential biases, such as item non-response, and how they were addressed. The use of Cronbach's alpha coefficients to assess the reliability of scales is an example of adding depth to your analysis. By combining quantitative data with qualitative insights, you create a comprehensive picture that enhances the credibility and impact of your research.
Ensuring the Robustness of Operationalized Variables
Cross-validation and replication studies.
In your research endeavors, cross-validation and replication studies are pivotal for affirming the robustness of your operationalized variables. Principles of replicability include clear methodology, transparent data sharing, independent verification, and reproducible analysis. These principles are not just theoretical ideals; they are practical steps that ensure the reliability of scientific findings. Documentation and collaboration are key for reliable research in scientific progress, and they facilitate the critical examination of results by the wider research community.
When you conduct replication studies, you are essentially retesting the operationalized variables in new contexts or with different samples. This can reveal the generalizability of your findings and highlight any contextual factors that may influence the outcomes. For instance, a study's results may vary when different researchers analyze the data independently, underscoring the importance of context in social sciences. Below is a list of considerations to keep in mind when planning for replication studies:
- Ensure that the methodology is thoroughly documented and shared.
- Seek independent verification of the findings by other researchers.
- Test the operationalized variables across different populations and settings.
- Be prepared for results that may differ from the original study, and explore the reasons why.
By adhering to these practices, you contribute to the cumulative knowledge in your field and enhance the credibility of your research.
Dealing with Confounding Variables
In your research, identifying and managing confounding variables is crucial to ensure the integrity of your findings. Confounding variables are external factors that can influence the outcome of your study, potentially leading to erroneous conclusions if not properly controlled. To mitigate their effects, it's essential to first recognize these variables during the design phase of your research.
Once identified, you can employ various strategies to control for confounders. Here are some common methods:
- Randomization : Assign subjects to treatment or control groups randomly to evenly distribute confounders.
- Matching : Pair subjects with similar characteristics to balance out confounding variables.
- Statistical control : Use regression or other statistical techniques to adjust for the influence of confounders.
Remember, the goal is to isolate the relationship between the independent and dependent variables by minimizing the impact of confounders. This process often involves revisiting and refining your experimental design to ensure that your results will be as accurate and reliable as possible.
Continuous Improvement of Measurement Methods
In the pursuit of scientific rigor, you must recognize the necessity for the continuous improvement of measurement methods. Measurements of abstract constructs have been criticized for their theoretical limitations, underscoring the importance of refinement and evolution in operationalization. To enhance the robustness of your research, consider the following steps:
- Regularly review the units and standards used to represent your variables' quantified values.
- Prioritize the inclusion of previously validated concepts and measures, especially those with strong psychometric properties across multiple languages and cultural contexts.
- Conduct follow-on experiments to test the reliability and validity of your measures.
- Engage in cross-validation with other studies to ensure consistency and generalizability.
By committing to these practices, you ensure that your operationalization process remains dynamic and responsive to new insights and methodologies.
The Impact of Operationalization on Research Outcomes
Influence on study validity.
The operationalization of variables is pivotal to the validity of your study. Operationalization ensures that the constructs you are examining are not only defined but also measured in a way that is consistent with your research objectives. This process directly impacts the credibility of your findings and the conclusions you draw.
When you operationalize a variable, you translate abstract concepts into measurable indicators . This translation is crucial because it allows you to collect data that can be analyzed statistically. For instance, if you are studying the concept of 'anxiety,' you might operationalize it by measuring heart rate, self-reported stress levels, or the frequency of anxiety-related behaviors.
Consider the following aspects to ensure that your operationalization strengthens the validity of your study:
- Conceptual clarity : Define your variables clearly to avoid ambiguity.
- Construct validity : Choose measures that accurately capture the theoretical constructs.
- Reliability : Use measurement methods that yield consistent results over time.
- Contextual relevance : Ensure that your operationalization is appropriate for the population and setting of your study.
By meticulously operationalizing your variables, you not only bolster the validity of your research but also enhance the trustworthiness of your findings within the scientific community.
Operationalization and Research Generalizability
The process of operationalization is pivotal in determining the generalizability of your research findings. Generalizability refers to the extent to which the results of a study can be applied to broader contexts beyond the specific conditions of the original research. By carefully operationalizing variables, you ensure that the constructs you measure are not only relevant within your study's framework but also resonate with external scenarios.
When operationalizing variables, consider the universality of the constructs. Are the variables culturally bound, or do they hold significance across different groups? This consideration is crucial for cross-cultural studies or research aiming for wide applicability. To illustrate, here's a list of factors that can influence generalizability:
- Cultural relevance of the operationalized variables
- The representativeness of the sample population
- The settings in which data is collected
- The robustness of the measurement instruments
Ensuring that these factors are addressed in your operationalization strategy can significantly enhance the generalizability of your research. Remember, the more universally applicable your operationalized variables are, the more impactful your research can be in contributing to the global body of knowledge.
Contributions to the Field of Study
Operationalization is not merely a methodological step in research; it is a transformative process that can significantly enhance the impact of your study. By meticulously converting theoretical constructs into measurable variables, you contribute to the field by enabling empirical testing of theories and facilitating the accumulation of knowledge. This process of quantification allows for the precise replication of research , which is essential for the advancement of science.
Your contributions through operationalization can be manifold. They may include the development of new measurement instruments, the refinement of existing scales, or the introduction of innovative ways to quantify complex constructs. Here's how your work can contribute to the field:
- Providing a clear basis for empirical inquiry
- Enhancing the precision of research findings
- Enabling cross-study comparisons and meta-analyses
- Informing policy decisions and practical applications
Each of these points reflects the broader significance of operationalization. It's not just about the numbers; it's about the clarity and applicability of research that can inform future studies, contribute to theory development, and ultimately, impact real-world outcomes.
Challenges and Solutions in Operationalizing Variables
Common pitfalls in operationalization.
Operationalizing variables is a critical step in research, yet it is fraught with challenges that can compromise the integrity of your study. One major pitfall is the misidentification of variables, which can lead to incorrect assumptions about causal relationships. Avoiding the inclusion of 'bad controls' that can confound results is essential. For instance, when dealing with observational data that includes many variables, it's easy to misspecify a model, leading to biased estimates.
Another common issue arises when researchers infer causal structure ex-post , which can be problematic without a correctly specified Directed Acyclic Graph (DAG). This underscores the importance of identifying causal structures ex-ante to ensure that the operationalization aligns with the true nature of the constructs being studied. Here are some key considerations to keep in mind:
- Ensure clarity in distinguishing between variables and constructs.
- Select variables based on clear criteria that align with your research questions.
- Validate the causal structure of your data before operationalization.
By being mindful of these aspects, you can mitigate the risks associated with operationalization and enhance the credibility of your research findings.
Adapting Operationalization in Evolving Research Contexts
As research contexts evolve, so must the methods of operationalization. The dynamic nature of social sciences, for instance, requires that operationalization be flexible enough to account for changes in environment and population. Outcomes that are valid in one context may not necessarily apply to another , necessitating a reevaluation of operational variables.
In the face of such variability, you can employ a structured approach to adapt your operationalization. Consider the following steps:
- Review the theoretical underpinnings of your constructs.
- Reassess the variables and their definitions in light of the new context.
- Modify measurement instruments to better capture the nuances of the changed environment.
- Conduct pilot studies to test the revised operationalization.
Furthermore, the integration of automation in research allows for a more nuanced operationalization process. You can select variables, define their operationalization, and customize statistical analyses to fit the evolving research landscape. This adaptability is crucial in ensuring that your research remains relevant and accurate over time.
Case Studies and Best Practices
In the realm of research, the operationalization of variables is a critical step that transforms abstract concepts into measurable entities. Case studies often illustrate the practical application of these principles, providing you with a blueprint for success. For instance, the ThinkIB guide on DP Psychology emphasizes the importance of clearly stating the independent and dependent variables when formulating a hypothesis. This clarity is paramount for the integrity of your research design.
Best practices suggest a structured approach to operationalization. Begin by identifying your variables and ensuring they align with your research objectives. Next, select appropriate measurement instruments that offer both validity and reliability. Finally, design your study to account for potential confounding variables and employ statistical techniques that will yield precise findings. Below is a list of steps that encapsulate these best practices:
- Clearly define your variables.
- Choose measurement instruments with care.
- Design a study that minimizes bias.
- Analyze data with appropriate statistical methods.
- Report findings with accuracy and detail.
By adhering to these steps and learning from the experiences of others, you can enhance the robustness of your research and contribute meaningful insights to your field of study.
Operationalizing variables is a critical step in research and data analysis, but it comes with its own set of challenges. From ensuring reliability and validity to dealing with the complexities of real-world data, researchers and analysts often need to find innovative solutions. If you're grappling with these issues, don't worry! Our website offers a wealth of resources and expert guidance to help you navigate the intricacies of operationalizing variables. Visit us now to explore our articles, tools, and support services designed to streamline your research process.
In conclusion, operationalizing variables is a critical step in the research process that transforms abstract concepts into measurable entities. This guide has delineated a systematic approach to quantifying research constructs, ensuring that they are empirically testable and scientifically valid. By carefully defining variables, selecting appropriate measurement scales, and establishing reliable and valid indicators, researchers can enhance the rigor of their studies and contribute to the advancement of knowledge in their respective fields. It is our hope that this step-by-step guide has demystified the operationalization process and provided researchers with the tools necessary to embark on their empirical inquiries with confidence and precision.
Frequently Asked Questions
What is operationalization in research.
Operationalization is the process of defining a research construct in measurable terms, specifying the exact operations involved in measuring it, and determining the method of data collection.
How do I differentiate between endogenous and exogenous variables?
Endogenous variables are the outcomes within a study that are influenced by other variables, while exogenous variables are external factors that influence the endogenous variables but are not influenced by them within the study's scope.
What criteria should I consider when selecting variables for operationalization?
Criteria include relevance to the research question, measurability, the potential for valid and reliable data collection, and the ability to be manipulated or observed within the study's design.
Why is ensuring validity and reliability important in measurement?
Validity ensures that the instrument measures what it's supposed to measure, while reliability ensures that the measurement results are consistent and repeatable over time.
How do I handle qualitative data in quantitative analysis?
Qualitative data can be quantified through coding, categorization, and the use of scales or indices to convert non-numerical data into a format that can be statistically analyzed.
What is a Structured Causal Model (SCM) in experimental design?
An SCM is a conceptual model that outlines the causal relationships between variables, helping researchers to understand and predict the effects of manipulating one or more variables.
What are some common pitfalls in operationalizing variables?
Common pitfalls include poorly defined constructs, using unreliable or invalid measurement instruments, and failing to account for confounding variables that may affect the results.
How does operationalization impact research outcomes?
Proper operationalization leads to more accurate and meaningful data, which in turn affects the validity and generalizability of the research findings, contributing to the field of study.

Discovering Statistics Using IBM SPSS Statistics: A Fun and Informative Guide

Unlocking the Power of Data: A Review of 'Essentials of Modern Business Statistics with Microsoft Excel'

Discovering Statistics Using SAS: A Comprehensive Review

Trending Topics for Your Thesis: What's Hot in 2024

How to Deal with a Total Lack of Motivation, Stress, and Anxiety When Finishing Your Master's Thesis

Mastering the First Step: How to Start Your Thesis with Confidence

Thesis Action Plan

Thesis Revision Made Simple: Techniques for Perfecting Your Academic Work
Integrating calm into your study routine: the power of mindfulness in education.
- Blog Articles
- Affiliate Program
- Terms and Conditions
- Payment and Shipping Terms
- Privacy Policy
- Return Policy
© 2024 Research Rebels, All rights reserved.
Your cart is currently empty.
- Interesting
- Scholarships
- UGC-CARE Journals
Types of Research Variable in Research with Example
What is the research variable and what are its types?

The research variable is a quantifying component that may change from time to time. In research, variables are like the building blocks that help us understand relationships between different factors. In this article, iLovePhD explains the main types of variables and what they mean with some real-world examples.
The terms variable and constant refer to changes in statistical patterns of random or real data that can lead to some changes in the resulting state of the system.
In other words, variables are any characteristics that can take on different values namely age, test marks, temperature, pressure, weight, etc.
Please enable JavaScript
Types of Research Variables with Examples
There are several types of research variables, including independent variables, dependent variables, and extraneous variables. Here’s an explanation of each type with examples:
- Independent Variables (IV)
- Dependent Variables (DV)
- Control Variables
- Extraneous Variables
- Mediating Variables
- Moderating Variables
Dependent and independent variables are measured during experimental studies to assess the cause-and-effect relationship.
1. What is a Dependent Variable in Research?
A dependent variable is a variable that varies concerning changes in the independent variable. The value of the dependent variable depends on the value of the independent variable. In statistics, dependent variables can be categorized into:
- Response variables (It varies with another variable)
- Outcome variables (It represents the outcome of another variable)
- Left-hand-side variables (It appears on the left-hand side of a regression equation)
The dependent variable is what we measure after varying the independent variable from low to high. This measurement is done to study the effect of the dependent variable on the independent variable by conducting statistical analyses. Based on the results, the degree to which the independent variable variation can be studied.
2. What is an Independent Variable?
An independent variable is a variable that we vary in an experimental study to measure its effects. It is called “independent” as it is not affected by any other variables in the study. Independent variables can be categorized into:
- Explanatory variables (It explains an event or result)
- Predictor variables (It predicts the value of a dependent variable)
- Right-hand-side variables (It appears on the right-hand side of a regression equation).
These terminologies are used in statistics, where we can study the degree to which an independent variable change can predict changes in the dependent variable.
Also Read: What is an Independent Variable ? Importance and Examples
Types of independent variables
There are two main types of independent variables.
- The experimental independent variables can be directly varied during the experimental study.
- A subject variable cannot be varied, but it can be used to group research subjects categorically.
The Independent variable is the cause. Its value is independent of other variables. The dependent variable is the effect. Its value is based on the changes in the independent variable. ilovephd .com
Example : Independent and dependent variables
You conduct a study to assess whether changes in pressure affect the reactor performance.
Your independent variable is the pressure of the reactor. You can vary the pressure by making it low for 30 minutes and high for another 30 minutes.
Your dependent variable is the performance of the reactor. Now, calculate the performance of the reactor and analyze the change in pressure have an effect on reactor performance.
How to Find Dependent and Independent Variables in Research?
Ascertaining dependent and independent variables can be difficult or tricky while designing research experiments. A dependent variable in one research study can be the independent variable in another study; therefore it’s important to identify the variables while formulating the design of experiments.
Tips to identify dependent variable type:
The following research questions can be used to identify the dependent variable:
- Is this variable calculated as an outcome of the study?
- Is this variable dependent on another variable in the experimental study?
- Is this variable calculated only after other variables are changed?
Tips to identify independent variable type:
The following research questions can be used to identify the independent variable:
- Is this variable controlled or varied as a subject grouping method?
- Does this variable come before the other variable in time?
- Is this variable used to study the effect of another variable?
Dependent and independent variables are used in the experimental and quasi-experimental research study. Some of the research questions and their dependent and independent variables are listed.

The results can be analyzed by generating descriptive statistics and an appropriate statistical test method can be used to test the research hypothesis . The type of test method depends on the type of variable, level of measurement, and number of independent variables. Most often, t-tests or ANOVA tests are used to assess the experimental data.
3. What are Control Variables?
Think of control variables as the things you want to keep constant so they don’t mess up your results. Going back to our studying methods example, let’s say you’re worried that the student’s prior knowledge might affect their scores. To control for this, you might make sure that all the students have similar levels of background knowledge before starting the study. By doing this, you’re preventing any outside factors from sneaking in and affecting your results.
- These are variables that are held constant or controlled to prevent them from confounding the relationship between the independent and dependent variables.
- They help ensure that any observed effects are due to the independent variable and not to other factors.
- Example: In the exercise and weight loss study, controlling for participants’ diet would be important to isolate the effects of exercise on weight loss.
4. What are Extraneous Variables?
These are like the unexpected guests at your research party – they can mess things up if you’re not careful. In our study, extraneous variables could be things like the students’ motivation levels, how much sleep they got the night before the exam, or even their access to study materials. These factors aren’t what we’re studying directly, but they could still influence the results if we’re not mindful of them.
- These are variables other than the independent and dependent variables that may influence the outcome of a study.
- They can introduce error or bias into the results if not controlled.
- Example: In the exercise and weight loss study, extraneous variables could include participants’ metabolism, genetics, or adherence to the exercise regimen.
5. What are Mediating Variables?
Sometimes, there’s a middleman in the relationship between our independent and dependent variables. Let’s say you’re studying the effect of stress on job performance. Coping mechanisms could be a mediating variable – they’re what’s happening in between the stress levels (independent variable) and how well someone does their job (dependent variable). Understanding these mediating variables helps us see the whole picture of what’s going on.
- These are variables that explain the relationship between the independent and dependent variables.
- They provide insight into the underlying mechanisms or processes through which the independent variable affects the dependent variable.
- Example: In a study on the relationship between stress (IV) and health outcomes (DV), coping mechanisms could serve as mediating variables, explaining how stress affects health.
6. What are Moderating Variables?
Finally, moderating variables are like the conditions or factors that can change the strength or direction of the relationship between our independent and dependent variables. For instance, in a study on the effects of exercise on mood, age could be a moderating variable. Maybe exercise has a stronger effect on mood for younger adults compared to older adults. Identifying these moderating variables helps us understand when and for whom our findings might hold.
- These are variables that influence the strength or direction of the relationship between the independent and dependent variables.
- They indicate under what conditions or for whom the relationship holds.
- Example: In a study on the effects of teaching methods (IV) on academic performance (DV), students’ prior knowledge could be a moderating variable, influencing how effective different teaching methods are for different students.
By understanding and considering these different types of variables, researchers can design more accurate studies and draw meaningful conclusions from their findings.
We hope that this article helps you to understand what is research variable and how to identify research variable types for designing experiments.

Hand-Picked Related Articles
Quantitative Vs Qualitative Research
What is Hypothesis in Research? Types, Examples, & Importance
- cause and effect relationship
- control variables
- Data Analysis
- Dependent Variable
- dependent variables
- experimental design
- hypothesis testing
- Independent Variable
- independent variables
- manipulating variables
- research conclusions
- research design
- research experiment
- research findings
- Research Methodology
- research reliability
- research validity
- Research Variable Example
- research variables
- scientific research
- statistical analysis
- Types of Research Variables

480 UGC CARE List of Journals – Science – 2024
100 cutting-edge research ideas in civil engineering, what is a phd a comprehensive guide for indian scientists and aspiring researchers, leave a reply cancel reply, most popular, top 488 scopus indexed journals in computer science – open access, scopus indexed journals list 2024, the nippon foundation fellowship programme 2025, fellowships in india 2024 -comprehensive guide, agi in research: unraveling the future of artificial intelligence, working sci-hub proxy links 2024: access research papers easily, abstract template for research paper, best for you, 24 best online plagiarism checker free – 2024, popular posts, popular category.
- POSTDOC 317
- Interesting 257
- Journals 236
- Fellowship 134
- Research Methodology 102
- All Scopus Indexed Journals 94
Mail Subscription

iLovePhD is a research education website to know updated research-related information. It helps researchers to find top journals for publishing research articles and get an easy manual for research tools. The main aim of this website is to help Ph.D. scholars who are working in various domains to get more valuable ideas to carry out their research. Learn the current groundbreaking research activities around the world, love the process of getting a Ph.D.
Contact us: [email protected]
Google News
Copyright © 2024 iLovePhD. All rights reserved
- Artificial intelligence
- Privacy Policy
Home » Research Methodology – Types, Examples and writing Guide
Research Methodology – Types, Examples and writing Guide
Table of Contents

Research Methodology
Definition:
Research Methodology refers to the systematic and scientific approach used to conduct research, investigate problems, and gather data and information for a specific purpose. It involves the techniques and procedures used to identify, collect , analyze , and interpret data to answer research questions or solve research problems . Moreover, They are philosophical and theoretical frameworks that guide the research process.
Structure of Research Methodology
Research methodology formats can vary depending on the specific requirements of the research project, but the following is a basic example of a structure for a research methodology section:
I. Introduction
- Provide an overview of the research problem and the need for a research methodology section
- Outline the main research questions and objectives
II. Research Design
- Explain the research design chosen and why it is appropriate for the research question(s) and objectives
- Discuss any alternative research designs considered and why they were not chosen
- Describe the research setting and participants (if applicable)
III. Data Collection Methods
- Describe the methods used to collect data (e.g., surveys, interviews, observations)
- Explain how the data collection methods were chosen and why they are appropriate for the research question(s) and objectives
- Detail any procedures or instruments used for data collection
IV. Data Analysis Methods
- Describe the methods used to analyze the data (e.g., statistical analysis, content analysis )
- Explain how the data analysis methods were chosen and why they are appropriate for the research question(s) and objectives
- Detail any procedures or software used for data analysis
V. Ethical Considerations
- Discuss any ethical issues that may arise from the research and how they were addressed
- Explain how informed consent was obtained (if applicable)
- Detail any measures taken to ensure confidentiality and anonymity
VI. Limitations
- Identify any potential limitations of the research methodology and how they may impact the results and conclusions
VII. Conclusion
- Summarize the key aspects of the research methodology section
- Explain how the research methodology addresses the research question(s) and objectives
Research Methodology Types
Types of Research Methodology are as follows:
Quantitative Research Methodology
This is a research methodology that involves the collection and analysis of numerical data using statistical methods. This type of research is often used to study cause-and-effect relationships and to make predictions.
Qualitative Research Methodology
This is a research methodology that involves the collection and analysis of non-numerical data such as words, images, and observations. This type of research is often used to explore complex phenomena, to gain an in-depth understanding of a particular topic, and to generate hypotheses.
Mixed-Methods Research Methodology
This is a research methodology that combines elements of both quantitative and qualitative research. This approach can be particularly useful for studies that aim to explore complex phenomena and to provide a more comprehensive understanding of a particular topic.
Case Study Research Methodology
This is a research methodology that involves in-depth examination of a single case or a small number of cases. Case studies are often used in psychology, sociology, and anthropology to gain a detailed understanding of a particular individual or group.
Action Research Methodology
This is a research methodology that involves a collaborative process between researchers and practitioners to identify and solve real-world problems. Action research is often used in education, healthcare, and social work.
Experimental Research Methodology
This is a research methodology that involves the manipulation of one or more independent variables to observe their effects on a dependent variable. Experimental research is often used to study cause-and-effect relationships and to make predictions.
Survey Research Methodology
This is a research methodology that involves the collection of data from a sample of individuals using questionnaires or interviews. Survey research is often used to study attitudes, opinions, and behaviors.
Grounded Theory Research Methodology
This is a research methodology that involves the development of theories based on the data collected during the research process. Grounded theory is often used in sociology and anthropology to generate theories about social phenomena.
Research Methodology Example
An Example of Research Methodology could be the following:
Research Methodology for Investigating the Effectiveness of Cognitive Behavioral Therapy in Reducing Symptoms of Depression in Adults
Introduction:
The aim of this research is to investigate the effectiveness of cognitive-behavioral therapy (CBT) in reducing symptoms of depression in adults. To achieve this objective, a randomized controlled trial (RCT) will be conducted using a mixed-methods approach.
Research Design:
The study will follow a pre-test and post-test design with two groups: an experimental group receiving CBT and a control group receiving no intervention. The study will also include a qualitative component, in which semi-structured interviews will be conducted with a subset of participants to explore their experiences of receiving CBT.
Participants:
Participants will be recruited from community mental health clinics in the local area. The sample will consist of 100 adults aged 18-65 years old who meet the diagnostic criteria for major depressive disorder. Participants will be randomly assigned to either the experimental group or the control group.
Intervention :
The experimental group will receive 12 weekly sessions of CBT, each lasting 60 minutes. The intervention will be delivered by licensed mental health professionals who have been trained in CBT. The control group will receive no intervention during the study period.
Data Collection:
Quantitative data will be collected through the use of standardized measures such as the Beck Depression Inventory-II (BDI-II) and the Generalized Anxiety Disorder-7 (GAD-7). Data will be collected at baseline, immediately after the intervention, and at a 3-month follow-up. Qualitative data will be collected through semi-structured interviews with a subset of participants from the experimental group. The interviews will be conducted at the end of the intervention period, and will explore participants’ experiences of receiving CBT.
Data Analysis:
Quantitative data will be analyzed using descriptive statistics, t-tests, and mixed-model analyses of variance (ANOVA) to assess the effectiveness of the intervention. Qualitative data will be analyzed using thematic analysis to identify common themes and patterns in participants’ experiences of receiving CBT.
Ethical Considerations:
This study will comply with ethical guidelines for research involving human subjects. Participants will provide informed consent before participating in the study, and their privacy and confidentiality will be protected throughout the study. Any adverse events or reactions will be reported and managed appropriately.
Data Management:
All data collected will be kept confidential and stored securely using password-protected databases. Identifying information will be removed from qualitative data transcripts to ensure participants’ anonymity.
Limitations:
One potential limitation of this study is that it only focuses on one type of psychotherapy, CBT, and may not generalize to other types of therapy or interventions. Another limitation is that the study will only include participants from community mental health clinics, which may not be representative of the general population.
Conclusion:
This research aims to investigate the effectiveness of CBT in reducing symptoms of depression in adults. By using a randomized controlled trial and a mixed-methods approach, the study will provide valuable insights into the mechanisms underlying the relationship between CBT and depression. The results of this study will have important implications for the development of effective treatments for depression in clinical settings.
How to Write Research Methodology
Writing a research methodology involves explaining the methods and techniques you used to conduct research, collect data, and analyze results. It’s an essential section of any research paper or thesis, as it helps readers understand the validity and reliability of your findings. Here are the steps to write a research methodology:
- Start by explaining your research question: Begin the methodology section by restating your research question and explaining why it’s important. This helps readers understand the purpose of your research and the rationale behind your methods.
- Describe your research design: Explain the overall approach you used to conduct research. This could be a qualitative or quantitative research design, experimental or non-experimental, case study or survey, etc. Discuss the advantages and limitations of the chosen design.
- Discuss your sample: Describe the participants or subjects you included in your study. Include details such as their demographics, sampling method, sample size, and any exclusion criteria used.
- Describe your data collection methods : Explain how you collected data from your participants. This could include surveys, interviews, observations, questionnaires, or experiments. Include details on how you obtained informed consent, how you administered the tools, and how you minimized the risk of bias.
- Explain your data analysis techniques: Describe the methods you used to analyze the data you collected. This could include statistical analysis, content analysis, thematic analysis, or discourse analysis. Explain how you dealt with missing data, outliers, and any other issues that arose during the analysis.
- Discuss the validity and reliability of your research : Explain how you ensured the validity and reliability of your study. This could include measures such as triangulation, member checking, peer review, or inter-coder reliability.
- Acknowledge any limitations of your research: Discuss any limitations of your study, including any potential threats to validity or generalizability. This helps readers understand the scope of your findings and how they might apply to other contexts.
- Provide a summary: End the methodology section by summarizing the methods and techniques you used to conduct your research. This provides a clear overview of your research methodology and helps readers understand the process you followed to arrive at your findings.
When to Write Research Methodology
Research methodology is typically written after the research proposal has been approved and before the actual research is conducted. It should be written prior to data collection and analysis, as it provides a clear roadmap for the research project.
The research methodology is an important section of any research paper or thesis, as it describes the methods and procedures that will be used to conduct the research. It should include details about the research design, data collection methods, data analysis techniques, and any ethical considerations.
The methodology should be written in a clear and concise manner, and it should be based on established research practices and standards. It is important to provide enough detail so that the reader can understand how the research was conducted and evaluate the validity of the results.
Applications of Research Methodology
Here are some of the applications of research methodology:
- To identify the research problem: Research methodology is used to identify the research problem, which is the first step in conducting any research.
- To design the research: Research methodology helps in designing the research by selecting the appropriate research method, research design, and sampling technique.
- To collect data: Research methodology provides a systematic approach to collect data from primary and secondary sources.
- To analyze data: Research methodology helps in analyzing the collected data using various statistical and non-statistical techniques.
- To test hypotheses: Research methodology provides a framework for testing hypotheses and drawing conclusions based on the analysis of data.
- To generalize findings: Research methodology helps in generalizing the findings of the research to the target population.
- To develop theories : Research methodology is used to develop new theories and modify existing theories based on the findings of the research.
- To evaluate programs and policies : Research methodology is used to evaluate the effectiveness of programs and policies by collecting data and analyzing it.
- To improve decision-making: Research methodology helps in making informed decisions by providing reliable and valid data.
Purpose of Research Methodology
Research methodology serves several important purposes, including:
- To guide the research process: Research methodology provides a systematic framework for conducting research. It helps researchers to plan their research, define their research questions, and select appropriate methods and techniques for collecting and analyzing data.
- To ensure research quality: Research methodology helps researchers to ensure that their research is rigorous, reliable, and valid. It provides guidelines for minimizing bias and error in data collection and analysis, and for ensuring that research findings are accurate and trustworthy.
- To replicate research: Research methodology provides a clear and detailed account of the research process, making it possible for other researchers to replicate the study and verify its findings.
- To advance knowledge: Research methodology enables researchers to generate new knowledge and to contribute to the body of knowledge in their field. It provides a means for testing hypotheses, exploring new ideas, and discovering new insights.
- To inform decision-making: Research methodology provides evidence-based information that can inform policy and decision-making in a variety of fields, including medicine, public health, education, and business.
Advantages of Research Methodology
Research methodology has several advantages that make it a valuable tool for conducting research in various fields. Here are some of the key advantages of research methodology:
- Systematic and structured approach : Research methodology provides a systematic and structured approach to conducting research, which ensures that the research is conducted in a rigorous and comprehensive manner.
- Objectivity : Research methodology aims to ensure objectivity in the research process, which means that the research findings are based on evidence and not influenced by personal bias or subjective opinions.
- Replicability : Research methodology ensures that research can be replicated by other researchers, which is essential for validating research findings and ensuring their accuracy.
- Reliability : Research methodology aims to ensure that the research findings are reliable, which means that they are consistent and can be depended upon.
- Validity : Research methodology ensures that the research findings are valid, which means that they accurately reflect the research question or hypothesis being tested.
- Efficiency : Research methodology provides a structured and efficient way of conducting research, which helps to save time and resources.
- Flexibility : Research methodology allows researchers to choose the most appropriate research methods and techniques based on the research question, data availability, and other relevant factors.
- Scope for innovation: Research methodology provides scope for innovation and creativity in designing research studies and developing new research techniques.
Research Methodology Vs Research Methods
| Research Methodology | Research Methods |
|---|---|
| Research methodology refers to the philosophical and theoretical frameworks that guide the research process. | refer to the techniques and procedures used to collect and analyze data. |
| It is concerned with the underlying principles and assumptions of research. | It is concerned with the practical aspects of research. |
| It provides a rationale for why certain research methods are used. | It determines the specific steps that will be taken to conduct research. |
| It is broader in scope and involves understanding the overall approach to research. | It is narrower in scope and focuses on specific techniques and tools used in research. |
| It is concerned with identifying research questions, defining the research problem, and formulating hypotheses. | It is concerned with collecting data, analyzing data, and interpreting results. |
| It is concerned with the validity and reliability of research. | It is concerned with the accuracy and precision of data. |
| It is concerned with the ethical considerations of research. | It is concerned with the practical considerations of research. |
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Research Gap – Types, Examples and How to...

Research Summary – Structure, Examples and...

Thesis Statement – Examples, Writing Guide

Research Problem – Examples, Types and Guide

Background of The Study – Examples and Writing...

Data Verification – Process, Types and Examples
Methods for Quantitative Research in Psychology
- Conducting Research
Psychological Research
August 2023

This seven-hour course provides a comprehensive exploration of research methodologies, beginning with the foundational steps of the scientific method. Students will learn about hypotheses, experimental design, data collection, and the analysis of results. Emphasis is placed on defining variables accurately, distinguishing between independent, dependent, and controlled variables, and understanding their roles in research.
The course delves into major research designs, including experimental, correlational, and observational studies. Students will compare and contrast these designs, evaluating their strengths and weaknesses in various contexts. This comparison extends to the types of research questions scientists pose, highlighting how different designs are suited to different inquiries.
A critical component of the course is developing the ability to judge the quality of sources for literature reviews. Students will learn criteria for evaluating the credibility, relevance, and reliability of sources, ensuring that their understanding of the research literature is built on a solid foundation.
Reliability and validity are key concepts addressed in the course. Students will explore what it means for an observation to be reliable, focusing on consistency and repeatability. They will also compare and contrast different forms of validity, such as internal, external, construct, and criterion validity, and how these apply to various research designs.
The course concepts are thoroughly couched in examples drawn from the psychological research literature. By the end of the course, students will be equipped with the skills to design robust research studies, critically evaluate sources, and understand the nuances of reliability and validity in scientific research. This knowledge will be essential for conducting high-quality research and contributing to the scientific community.
Learning objectives
- Describe the steps of the scientific method.
- Specify how variables are defined.
- Compare and contrast the major research designs.
- Explain how to judge the quality of a source for a literature review.
- Compare and contrast the kinds of research questions scientists ask.
- Explain what it means for an observation to be reliable.
- Compare and contrast forms of validity as they apply to the major research designs.
This program does not offer CE credit.
More in this series
Introduces applying statistical methods effectively in psychology or related fields for undergraduates, high school students, and professionals.
August 2023 On Demand Training
Introduces the importance of ethical practice in scientific research for undergraduates, high school students, and professionals.
Independent Variable (Treatment Variable) Definition and Uses
Types of Variable > Independent Variable
- Independent Variable
- Predictor Variable
1. Independent Variable Definition.
Independent variables are variables that stand on their own and aren’t affected by anything that you, as a researcher, do. You have complete control over which independent variables you choose. During an experiment, you usually choose independent variables that you think will affect dependent variables . Those are variables that can be changed by outside factors. If a variable is classified as a control variable , it may be thought to alter either the independent variable or dependent variable but it isn’t the focus of the experiment.
Example : you want to know how calorie intake affects weight. Calorie intake is your independent variable and weight is your dependent variable. You can choose the calories given to participants, and you see how that independent variable affects the weights. You may decide to include a control variable of age in your study to see if it affects the outcome.

Another way of looking at independent variables is that they cause something (or are thought to cause something). In the above example, the independent variable is calorie consumption. That’s thought to cause weight gain (or loss).
Independent Variables: Other Names and Uses.

Independent variables are also called the “inputs” for functions. They are traditionally plotted on the x-axis of a graph. Dependent variables are usually plotted on the y-axis. Sometimes it’s possible to switch the two variables around (i.e. switch independent to dependent), but it can be challenging to see if it makes sense. A helpful tool is the vertical line test , which will tell you whether or not the switch resulted in a function (functions are necessary for the bulk of statistical analysis).
In statistics, an independent variable is also sometimes called:
- A controlled variable.
- An explanatory variable.
- An exposure variable (in reliability theory).
- A feature (in machine learning and pattern recognition).
- An input variable.
- A manipulated variable.
- A predictor variable .
- A regressor (in regression analysis ).
- A risk factor (in medical statistics).
What is a Predictor Variable?

- In regression analysis , where the predictor variable is also called a regressor . The other variable (comparable to the dependent variable) is called a criterion variable .
- In non-experimental studies, where it is the presumed “cause.” For example, scores on a math test indicate an aptitude for engineering. “Scores on the math test” are the predictor variables and engineering aptitude is the criterion variable.
Types of Predictor Variable.
The two main types are:
- Quantitative Predictors , which have a numerical value (i.e. 5.5,800,2K) for categories like age, height, test scores or weight.
- Qualitative Predictors , which do not have numerical values. Used for categories like gender, socioeconomic status, political affiliation or geographic location.
A common workaround to working with qualitative predictors is to assign them to a numerical class when performing correlational studies. For example, if you were performing a study that was looking at the effect of sex and income, you might assign the following classes:
- Transgender woman(3).
- Transgender man(4).
When you only have two classes coded 0 or 1, it’s called a dummy variable . Dummy variables can make it easier to understand the results from a regression analysis. Other codings, like 2/3 or 8/9 can also be used (they just make the output more difficult to comprehend).
Multiple Predictor Variables
Some regression models can include dozens of predictor variables. That’s a model that Professor David Dranove of the Kellogg school of management calls the “kitchen sink” regression method. It’s possible for thousands of potential predictor variables to make up a data set, so care should be taken in choosing which ones you use for your analysis. There are several reasons for this, one of which is the more variables you throw in to the mix, the weaker your model. Some rules of thumb for choosing variables:
- Select a maximum of one predictor variable for every five observations, if your predictive model is good.
- Use a maximum of one predictor variable for every ten observations if your predictive model is weak, or if you have a slew of variables to choose from.
- If you have categorical variables , treat each included one as half of a normal predictor.
Levels of Independent Variable
While you might study one IV for a science fair project, it more common to have many levels of the same IV. You can think of a “level” as a sub type of the IV. For example, you might be studying weight loss for three different diets: Atkins, Paleo, and Vegan. The three diets are the three levels of Independent Variable. Or, you could have an experiment where you are comparing two treatments: placebo and experimental. In that case, you have two levels.
Reference: Dranove, P. Retrieved 12-2015 from: https://www.kellogg.northwestern.edu/faculty/dranove/htm/Dranove/coursepages/Mgmt%20469/choosing%20variables.pdf UNM.EDU. Retrieved 12-2015 from: http://math-cobalt.oit.umn.edu/function_machine
We Trust in Human Precision
20,000+ Professional Language Experts Ready to Help. Expertise in a variety of Niches.
API Solutions
- API Pricing
- Cost estimate
- Customer loyalty program
- Educational Discount
- Non-Profit Discount
- Green Initiative Discount1
Value-Driven Pricing
Unmatched expertise at affordable rates tailored for your needs. Our services empower you to boost your productivity.
- Special Discounts
- Enterprise transcription solutions
- Enterprise translation solutions
- Transcription/Caption API
- AI Transcription Proofreading API
Trusted by Global Leaders
GoTranscript is the chosen service for top media organizations, universities, and Fortune 50 companies.
GoTranscript
One of the Largest Online Transcription and Translation Agencies in the World. Founded in 2005.
Speaker 1: In this video, we're going to unpack the two related concepts of research constructs and research variables so that you can understand what they are, how they're different, and how to use them correctly in your research project. Let's do it. So first, let's start with a big picture view and then we can zoom into the finer details. Research constructs and variables both relate to the things of interest that you're going to explore within your study. For example, let's say you're interested in job satisfaction and more specifically you're interested in what factors impact an employee's job satisfaction. In this case, both job satisfaction and all of those things, those factors that might impact job satisfaction, would be considered either constructs or variables. So as you can see, constructs and variables are pretty central to any research project because they link directly to the things that you're interested in investigating. But it's important to say that these two things are different and we're going to unpack how they're different in this video. Before digging deeper though, it's worth mentioning that this video is based on an extract from our popular online course, Research Methodology Bootcamp. If you're new to formal academic research and research methodology specifically, you'll definitely want to check that out. And to say thanks for watching this video, we've got a special 60% off discount offer just for you. You can find the link to that in the description. So let's start with research constructs. Simply put, a research construct is an abstraction that researchers use to represent a phenomenon that's not directly measurable. For example, intelligence, motivation, or agreeableness would all be constructs because they're not directly observable and measurable. Since constructs aren't directly measurable, they have to be inferred from other indicators that are measurable or which can be directly observed. For example, the construct of intelligence can be inferred based on a combination of more quantifiable factors like IQ scores and language proficiency levels, both of which can be directly observed and measured. As a researcher, it's really important for you to clearly define your constructs and to make sure that they can be operationalized. In other words, you'll need to think about how you can develop ways to measure these abstract concepts or constructs using relevant indicators or proxies that accurately reflect the underlying phenomenon that you're interested in. In technical terms, this is called construct validity. If you want to learn more about that, we've got a dedicated video covering construct validity, and again, you can find the link to that in the description. Now that we've looked at constructs, let's move on to variables. Now, it's worth mentioning that within research, the terms construct and variable are often used quite loosely and sometimes even interchangeably, but as I mentioned, they're not the same thing. A variable refers to a phenomenon that is directly measurable and that can take on different values or levels. For example, things like someone's age or heart or weight and even their blood pressure would all be considered variables as these things can be directly observed and quantified using some sort of measurement instrument. Typically, constructs are more abstract than variables since they represent broader ideas and concepts, while variables are really specific measures within those concepts. In other words, as a researcher, you'll typically need to use a combination of variables if your aim is to measure a construct. Thinking back to the example that we looked at earlier, intelligence would be a construct, while IQ score and language proficiency levels would be two potential variables that you could use to measure that construct of intelligence. Now, it's important to mention that it's not always the case that a researcher wants to measure a construct. Oftentimes, research projects have other aims, for example, to explore how people experience something or the emotions that they attach to a certain phenomena or to a certain construct. So, long story short, while there is this relationship between variables and constructs, in other words, you can use a combination of variables to measure a construct, it's not always the case that you need both of these. Quite commonly, constructs will be the focus within qualitative research, while variables will be front and center within quantitative research. But that's not to say that quantitative studies never explore constructs, it's just that they use a combination of variables to do that. It's also worth mentioning that there are multiple different types of variables. So, you may have heard of things like dependent variables and independent variables, moderators and mediating variables, and so on. If you are keen to learn more about variables, we've got a dedicated video that unpacks all of that terminology, and again, you can find the link in the description. Now that we've unpacked what both constructs and variables are and how they differ, let's look at a few practical examples to solidify your understanding. A great example of a research construct is motivation. It's something that we can all relate to, whether that's high motivation or low motivation, but it's also something that we can probably all agree is pretty difficult to quantify and to measure. If you wanted to quantify motivation levels in a study, you could consider using self-reported motivation scales, for example, the situational motivation scale or the sports motivation scale. These are basic survey tools where people respond to a set of statements relating to their motivation levels. Another way that you could potentially measure motivation is by observing participants' actual behavior and assessing their level of motivation based on their level of persistence when they pursue a specific goal. For example, how much time do they spend or how many attempts do they make to achieve a certain goal? This would be another way in which you could quantify motivation. Another good example of a research construct is social capital. In other words, the quality and quantity of resources and connections that an individual has within a social network. To measure this construct, you could look at variables such as the person's network size. In other words, how many people do they know? You could also look at the diversity of that network, however you might define that, for example, age or gender or income level and so on. And so these factors would give you quantifiable variables which together you could use to assess the research construct of social capital. So to summarize, as you can see in both of these examples, the research construct or a research construct is more abstract and it's less directly observable, whereas the research variables are directly observable and most importantly measurable. So while these two things, research constructs and research variables, are similar in that they're both interested in your things of interest within your research study, they're not the same thing. And so don't make that mistake when you're writing up your research methodology. Alright, so hopefully you now have a clearer understanding of the two related concepts of constructs and variables. If you got value from this video, please do hit that like button so that more people can find this content. If you're currently working on a research paper or a dissertation or a thesis, you'll definitely also want to subscribe to the Grad Coach channel for loads of practical tutorials and tips to help you fast track your research journey. Alternatively, if you'd like hands-on help with your research project, be sure to check out our private coaching service where we hold your hand throughout the research process, step by step. If you're interested in that, you can learn more and book a free initial consultation over at gradcoach.com. you

Pardon Our Interruption
As you were browsing something about your browser made us think you were a bot. There are a few reasons this might happen:
- You've disabled JavaScript in your web browser.
- You're a power user moving through this website with super-human speed.
- You've disabled cookies in your web browser.
- A third-party browser plugin, such as Ghostery or NoScript, is preventing JavaScript from running. Additional information is available in this support article .
To regain access, please make sure that cookies and JavaScript are enabled before reloading the page.
How To Make Conceptual Framework (With Examples and Templates)

We all know that a research paper has plenty of concepts involved. However, a great deal of concepts makes your study confusing.
A conceptual framework ensures that the concepts of your study are organized and presented comprehensively. Let this article guide you on how to make the conceptual framework of your study.
Related: How to Write a Concept Paper for Academic Research
Table of Contents
At a glance: free conceptual framework templates.
Too busy to create a conceptual framework from scratch? No problem. We’ve created templates for each conceptual framework so you can start on the right foot. All you need to do is enter the details of the variables. Feel free to modify the design according to your needs. Please read the main article below to learn more about the conceptual framework.
Conceptual Framework Template #1: Independent-Dependent Variable Model
Conceptual framework template #2: input-process-output (ipo) model, conceptual framework template #3: concept map, what is a conceptual framework.
A conceptual framework shows the relationship between the variables of your study. It includes a visual diagram or a model that summarizes the concepts of your study and a narrative explanation of the model presented.
Why Should Research Be Given a Conceptual Framework?
Imagine your study as a long journey with the research result as the destination. You don’t want to get lost in your journey because of the complicated concepts. This is why you need to have a guide. The conceptual framework keeps you on track by presenting and simplifying the relationship between the variables. This is usually done through the use of illustrations that are supported by a written interpretation.
Also, people who will read your research must have a clear guide to the variables in your study and where the research is heading. By looking at the conceptual framework, the readers can get the gist of the research concepts without reading the entire study.
Related: How to Write Significance of the Study (with Examples)
What Is the Difference Between Conceptual Framework and Theoretical Framework?
| You can develop this through the researcher’s specific concept in the study. | Purely based on existing theories. |
| The research problem is backed up by existing knowledge regarding things the researcher wants us to discover about the topic. | The research problem is supported using past relevant theories from existing literature. |
| Based on acceptable and logical findings. | It is established with the help of the research paradigm. |
| It emphasizes the historical background and the structure to fill in the knowledge gap. | A general set of ideas and theories is essential in writing this area. |
| It highlights the fundamental concepts characterizing the study variable. | It emphasizes the historical background and the structure to fill the knowledge gap. |
Both of them show concepts and ideas of your study. The theoretical framework presents the theories, rules, and principles that serve as the basis of the research. Thus, the theoretical framework presents broad concepts related to your study. On the other hand, the conceptual framework shows a specific approach derived from the theoretical framework. It provides particular variables and shows how these variables are related.
Let’s say your research is about the Effects of Social Media on the Political Literacy of College Students. You may include some theories related to political literacy, such as this paper, in your theoretical framework. Based on this paper, political participation and awareness determine political literacy.
For the conceptual framework, you may state that the specific form of political participation and awareness you will use for the study is the engagement of college students on political issues on social media. Then, through a diagram and narrative explanation, you can show that using social media affects the political literacy of college students.
What Are the Different Types of Conceptual Frameworks?
The conceptual framework has different types based on how the research concepts are organized 1 .
1. Taxonomy
In this type of conceptual framework, the phenomena of your study are grouped into categories without presenting the relationship among them. The point of this conceptual framework is to distinguish the categories from one another.
2. Visual Presentation
In this conceptual framework, the relationship between the phenomena and variables of your study is presented. Using this conceptual framework implies that your research provides empirical evidence to prove the relationship between variables. This is the type of conceptual framework that is usually used in research studies.
3. Mathematical Description
In this conceptual framework, the relationship between phenomena and variables of your study is described using mathematical formulas. Also, the extent of the relationship between these variables is presented with specific quantities.
How To Make Conceptual Framework: 4 Steps
1. identify the important variables of your study.
There are two essential variables that you must identify in your study: the independent and the dependent variables.
An independent variable is a variable that you can manipulate. It can affect the dependent variable. Meanwhile, the dependent variable is the resulting variable that you are measuring.
You may refer to your research question to determine your research’s independent and dependent variables.
Suppose your research question is: “Is There a Significant Relationship Between the Quantity of Organic Fertilizer Used and the Plant’s Growth Rate?” The independent variable of this study is the quantity of organic fertilizer used, while the dependent variable is the plant’s growth rate.
2. Think About How the Variables Are Related
Usually, the variables of a study have a direct relationship. If a change in one of your variables leads to a corresponding change in another, they might have this kind of relationship.
However, note that having a direct relationship between variables does not mean they already have a cause-and-effect relationship 2 . It takes statistical analysis to prove causation between variables.
Using our example earlier, the quantity of organic fertilizer may directly relate to the plant’s growth rate. However, we are not sure that the quantity of organic fertilizer is the sole reason for the plant’s growth rate changes.
3. Analyze and Determine Other Influencing Variables
Consider analyzing if other variables can affect the relationship between your independent and dependent variables 3 .
4. Create a Visual Diagram or a Model
Now that you’ve identified the variables and their relationship, you may create a visual diagram summarizing them.
Usually, shapes such as rectangles, circles, and arrows are used for the model. You may create a visual diagram or model for your conceptual framework in different ways. The three most common models are the independent-dependent variable model, the input-process-output (IPO) model, and concept maps.
a. Using the Independent-Dependent Variable Model
You may create this model by writing the independent and dependent variables inside rectangles. Then, insert a line segment between them, connecting the rectangles. This line segment indicates the direct relationship between these variables.
Below is a visual diagram based on our example about the relationship between organic fertilizer and a plant’s growth rate.
 1")
b. Using the Input-Process-Output (IPO) Model
If you want to emphasize your research process, the input-process-output model is the appropriate visual diagram for your conceptual framework.
To create your visual diagram using the IPO model, follow these steps:
- Determine the inputs of your study . Inputs are the variables you will use to arrive at your research result. Usually, your independent variables are also the inputs of your research. Let’s say your research is about the Level of Satisfaction of College Students Using Google Classroom as an Online Learning Platform. You may include in your inputs the profile of your respondents and the curriculum used in the online learning platform.
- Outline your research process. Using our example above, the research process should be like this: Data collection of student profiles → Administering questionnaires → Tabulation of students’ responses → Statistical data analysis.
- State the research output . Indicate what you are expecting after you conduct the research. In our example above, the research output is the assessed level of satisfaction of college students with the use of Google Classroom as an online learning platform.
- Create the model using the research’s determined input, process, and output.
Presented below is the IPO model for our example above.
 2")
c. Using Concept Maps
If you think the two models presented previously are insufficient to summarize your study’s concepts, you may use a concept map for your visual diagram.
A concept map is a helpful visual diagram if multiple variables affect one another. Let’s say your research is about Coping with the Remote Learning System: Anxiety Levels of College Students. Presented below is the concept map for the research’s conceptual framework:
 3")
5. Explain Your Conceptual Framework in Narrative Form
Provide a brief explanation of your conceptual framework. State the essential variables, their relationship, and the research outcome.
Using the same example about the relationship between organic fertilizer and the growth rate of the plant, we can come up with the following explanation to accompany the conceptual framework:
Figure 1 shows the Conceptual Framework of the study. The quantity of the organic fertilizer used is the independent variable, while the plant’s growth is the research’s dependent variable. These two variables are directly related based on the research’s empirical evidence.
Conceptual Framework in Quantitative Research
You can create your conceptual framework by following the steps discussed in the previous section. Note, however, that quantitative research has statistical analysis. Thus, you may use arrows to indicate a cause-and-effect relationship in your model. An arrow implies that your independent variable caused the changes in your dependent variable.
Usually, for quantitative research, the Input-Process-Output model is used as a visual diagram. Here is an example of a conceptual framework in quantitative research:
Research Topic : Level of Effectiveness of Corn (Zea mays) Silk Ethanol Extract as an Antioxidant
 4")
Conceptual Framework in Qualitative Research
Again, you can follow the same step-by-step guide discussed previously to create a conceptual framework for qualitative research. However, note that you should avoid using one-way arrows as they may indicate causation . Qualitative research cannot prove causation since it uses only descriptive and narrative analysis to relate variables.
Here is an example of a conceptual framework in qualitative research:
Research Topic : Lived Experiences of Medical Health Workers During Community Quarantine
 5")
Conceptual Framework Examples
Presented below are some examples of conceptual frameworks.
Research Topic : Hypoglycemic Ability of Gabi (Colocasia esculenta) Leaf Extract in the Blood Glucose Level of Swiss Mice (Mus musculus)
 6")
Figure 1 presents the Conceptual Framework of the study. The quantity of gabi leaf extract is the independent variable, while the Swiss mice’s blood glucose level is the study’s dependent variable. This study establishes a direct relationship between these variables through empirical evidence and statistical analysis .
Research Topic : Level of Effectiveness of Using Social Media in the Political Literacy of College Students
 7")
Figure 1 shows the Conceptual Framework of the study. The input is the profile of the college students according to sex, year level, and the social media platform being used. The research process includes administering the questionnaires, tabulating students’ responses, and statistical data analysis and interpretation. The output is the effectiveness of using social media in the political literacy of college students.
Research Topic: Factors Affecting the Satisfaction Level of Community Inhabitants
 8")
Figure 1 presents a visual illustration of the factors that affect the satisfaction level of community inhabitants. As presented, environmental, societal, and economic factors influence the satisfaction level of community inhabitants. Each factor has its indicators which are considered in this study.
Tips and Warnings
- Please keep it simple. Avoid using fancy illustrations or designs when creating your conceptual framework.
- Allot a lot of space for feedback. This is to show that your research variables or methodology might be revised based on the input from the research panel. Below is an example of a conceptual framework with a spot allotted for feedback.
 9")
Frequently Asked Questions
1. how can i create a conceptual framework in microsoft word.
First, click the Insert tab and select Shapes . You’ll see a wide range of shapes to choose from. Usually, rectangles, circles, and arrows are the shapes used for the conceptual framework.
 10")
Next, draw your selected shape in the document.
 11")
Insert the name of the variable inside the shape. You can do this by pointing your cursor to the shape, right-clicking your mouse, selecting Add Text , and typing in the text.
 12")
Repeat the same process for the remaining variables of your study. If you need arrows to connect the different variables, you can insert one by going to the Insert tab, then Shape, and finally, Lines or Block Arrows, depending on your preferred arrow style.
2. How to explain my conceptual framework in defense?
If you have used the Independent-Dependent Variable Model in creating your conceptual framework, start by telling your research’s variables. Afterward, explain the relationship between these variables. Example: “Using statistical/descriptive analysis of the data we have collected, we are going to show how the <state your independent variable> exhibits a significant relationship to <state your dependent variable>.”
On the other hand, if you have used an Input-Process-Output Model, start by explaining the inputs of your research. Then, tell them about your research process. You may refer to the Research Methodology in Chapter 3 to accurately present your research process. Lastly, explain what your research outcome is.
Meanwhile, if you have used a concept map, ensure you understand the idea behind the illustration. Discuss how the concepts are related and highlight the research outcome.
3. In what stage of research is the conceptual framework written?
The research study’s conceptual framework is in Chapter 2, following the Review of Related Literature.
4. What is the difference between a Conceptual Framework and Literature Review?
The Conceptual Framework is a summary of the concepts of your study where the relationship of the variables is presented. On the other hand, Literature Review is a collection of published studies and literature related to your study.
Suppose your research concerns the Hypoglycemic Ability of Gabi (Colocasia esculenta) Leaf Extract on Swiss Mice (Mus musculus). In your conceptual framework, you will create a visual diagram and a narrative explanation presenting the quantity of gabi leaf extract and the mice’s blood glucose level as your research variables. On the other hand, for the literature review, you may include this study and explain how this is related to your research topic.
5. When do I use a two-way arrow for my conceptual framework?
You will use a two-way arrow in your conceptual framework if the variables of your study are interdependent. If variable A affects variable B and variable B also affects variable A, you may use a two-way arrow to show that A and B affect each other.
Suppose your research concerns the Relationship Between Students’ Satisfaction Levels and Online Learning Platforms. Since students’ satisfaction level determines the online learning platform the school uses and vice versa, these variables have a direct relationship. Thus, you may use two-way arrows to indicate that the variables directly affect each other.
- Conceptual Framework – Meaning, Importance and How to Write it. (2020). Retrieved 27 April 2021, from https://afribary.com/knowledge/conceptual-framework/
- Correlation vs Causation. Retrieved 27 April 2021, from https://www.jmp.com/en_ph/statistics-knowledge-portal/what-is-correlation/correlation-vs-causation.html
- Swaen, B., & George, T. (2022, August 22). What is a conceptual framework? Tips & Examples. Retrieved December 5, 2022, from https://www.scribbr.com/methodology/conceptual-framework/
Written by Jewel Kyle Fabula
in Career and Education , Juander How

Jewel Kyle Fabula
Jewel Kyle Fabula is a Bachelor of Science in Economics student at the University of the Philippines Diliman. His passion for learning mathematics developed as he competed in some mathematics competitions during his Junior High School years. He loves cats, playing video games, and listening to music.
Browse all articles written by Jewel Kyle Fabula
Copyright Notice
All materials contained on this site are protected by the Republic of the Philippines copyright law and may not be reproduced, distributed, transmitted, displayed, published, or broadcast without the prior written permission of filipiknow.net or in the case of third party materials, the owner of that content. You may not alter or remove any trademark, copyright, or other notice from copies of the content. Be warned that we have already reported and helped terminate several websites and YouTube channels for blatantly stealing our content. If you wish to use filipiknow.net content for commercial purposes, such as for content syndication, etc., please contact us at legal(at)filipiknow(dot)net
- School Guide
- Mathematics
- Number System and Arithmetic
- Trigonometry
- Probability
- Mensuration
- Maths Formulas
- Class 8 Maths Notes
- Class 9 Maths Notes
- Class 10 Maths Notes
- Class 11 Maths Notes
- Class 12 Maths Notes
Variables in Research
In the realm of research, particularly in mathematics and the sciences understanding the concept of the variables is fundamental. The Variables are integral to the formulation of hypotheses the design of the experiments and interpretation of data. They serve as the building blocks for the mathematical models and statistical analyses making it possible to describe, analyze and predict phenomena.
This article aims to provide a comprehensive overview of the variables in the research explaining their significance, types and roles. By the end of this article, students and researchers will have a clearer understanding of how to identify, use and interpret variables in their research projects.
Table of Content
What are Variables?
Types of variables, independent variables, dependent variables, control variables, extraneous variables, moderator variables, mediator variables.
Variables are elements that can change or vary within the experiment or study. They can represent different types of data such as numerical values, categories or even qualitative attributes. In mathematical terms, variables are symbols that can assume different values.
Various types of variables are:
Definition: Variables that are manipulated or controlled in an experiment to observe their effect on other variables.
Example: In a study examining the effect of study time on the test scores the amount of the study time is the independent variable.
Definition: Variables that are measured or observed in response to the changes in the independent variable.
Example: In the same study the test scores are the dependent variable.
Definition: Variables that are kept constant to ensure that the results are due to the manipulation of the independent variable.
Example: The study environment could be a control variable in the study on the study time and test scores.
Definition: Variables that are not intentionally studied but could affect the outcome of the experiment.
Example: The amount of the sleep students get before the test could be an extraneous variable.
Definition: V ariables that influence the strength or direction of the relationship between independent and dependent variables.
Example: The difficulty of the test could be a moderator variable affecting the relationship between the study time and test scores.
Definition: Variables that explain the process through which the independent variable affects the dependent variable.
Example: The level of the understanding of the material could be a mediator variable in the study on study time and test scores.
Role of Variables in Research
Variables are crucial in research for the several reasons:
- Formulating Hypotheses: Variables help in defining and formulating hypotheses in which are essential for the conducting experiments and studies.
- Designing Experiments: Variables determine the structure and design of the experiments guiding the procedures for the data collection and analysis.
- Analyzing Data: Understanding the relationships between the variables is key to the analyzing data and drawing meaningful conclusions from the research.
- Predicting Outcomes: Variables are used in mathematical models to the predict outcomes and make informed decisions based on the data.
Example: Using Variables in a Mathematical Research Study
Let’s consider a study investigating the relationship between the number of the hours spent practicing a mathematical problem and the performance on the test.
- Independent Variable: Number of hours spent practicing.
- Dependent Variable: Test performance (score).
- Control Variable: Type of the mathematical problems practiced.
- Extraneous Variable: Prior knowledge of the subject.
- Moderator Variable: Complexity of the problems.
- Mediator Variable: Confidence level of the student.
Step-by-Step Example
Formulating the Hypothesis: “Increasing the number of hours spent practicing mathematical problems will improve the test performance.”
- Designing Experiment: Students are divided into groups based on the different practice hours (1 hour, 2 hours, 3 hours).
- Data Collection: Test scores are collected after the practice sessions.
- Data Analysis: The relationship between the practice hours and test scores is analyzed using the statistical methods.
- Conclusion: The findings are used to the draw conclusions about the impact of the practice on test performance.
Visualizing Data
Visualizing data helps in understanding the relationships between the variables. Here are some common methods:
- Scatter Plots: To visualize the relationship between the two continuous variables.
- Bar Charts: To compare the means of the different groups.
- Histograms: To show the distribution of the single variable.
Questions on Variables in Research
Question 1: In a study examining the effect of the sleep on the academic performance identify the independent, dependent and control variables.
Independent Variable: Amount of sleep. Dependent Variable: Academic performance (grades). Control Variable: Study environment, type of the academic tasks.
Question 2: Explain how an extraneous variable can affect the outcome of an experiment.
An extraneous variable such as the amount of the caffeine consumed could affect the academic performance of the students in a study examining the effect of sleep on the academic performance. If not controlled it could confound the results by the influencing the dependent variable independently of the independent variable.
Question 3: Describe how you would control for extraneous variables in a study.
To control for the extraneous variables researchers can use the random assignment ensure consistent conditions or include the extraneous variables in the statistical analysis to the account for their potential impact.
Practice Questions on Variables in Research
Q1: How can you identify the independent variable in a given research study?
Q2: What steps can you take to ensure that control variables are effectively managed in an experiment?
Q3: How does the presence of extraneous variables impact the validity of research findings?
Q4: In what ways can a moderator variable affect the relationship between independent and dependent variables?
Q5: What are some common methods for visualizing the relationship between independent and dependent variables?
Q6: How can you determine if a variable should be classified as a mediator in your research?
Q7: What are the key differences between categorical and continuous variables, and how do they influence data analysis?
Q8: How do you formulate a hypothesis involving multiple variables in a complex study?
Q9: What strategies can be employed to reduce the impact of extraneous variables in field research?
Q10: How can statistical methods be used to account for control variables in the analysis of research data?
Variables are the cornerstone of the research in mathematics and other sciences. They allow researchers to the formulate hypotheses, design experiments analyze data and draw meaningful conclusions. By understanding and effectively managing different types of the variables researchers can enhance the validity and reliability of their studies.
Concept of variable and Raw data Dependent and Independent variable
FAQs on Variables in Research
What is an independent variable.
An independent variable is the variable that is manipulated in an experiment to the observe its effect on the dependent variable.
What is a dependent variable?
A dependent variable is the variable that is measured or observed in the response to the changes in the independent variable.
Why are control variables important?
Control variables are important because they help ensure that the results of an experiment are due to the manipulation of the independent variable and not other factors.
What is the difference between moderator and mediator variables?
Moderator variables influence the strength or direction of the relationship between the independent and dependent variables while mediator variables explain the process through which the independent variable affects the dependent variable.
Please Login to comment...
Similar reads.
- School Learning
- How to Delete Discord Servers: Step by Step Guide
- Google increases YouTube Premium price in India: Check our the latest plans
- California Lawmakers Pass Bill to Limit AI Replicas
- Best 10 IPTV Service Providers in Germany
- Content Improvement League 2024: From Good To A Great Article
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
How to Use Computer Vision to Blur Your Screen
Roboflow Workflows is a low-code computer vision application builder. With Workflows, you can build multi-step computer vision workflows in a browser editor. You can then deploy your Workflows using the Roboflow API, a Dedicated Deployment, or on your own hardware.
In this guide, we’ll explore how to use traditional computer vision techniques to automatically blur your screen during sensitive moments, such as when switching between tabs or browsers. This could be used by live streamers to blur a screen while switching tabs, reducing the chance a tab is accidentally opened with sensitive information visible.
Here is a demo of the system in use:
Here are the steps we will follow in this guide:
- Create a workflow that calculates the dominant colour in a region
Install and import libraries
Define needed variables.
- Create blur function that runs when the dominant colour changes, indicative of a tab change.
- Run the Workflow with OBS on your computer
Let’s start building!
Create a Workflow
Our end workflow will look similar to this:
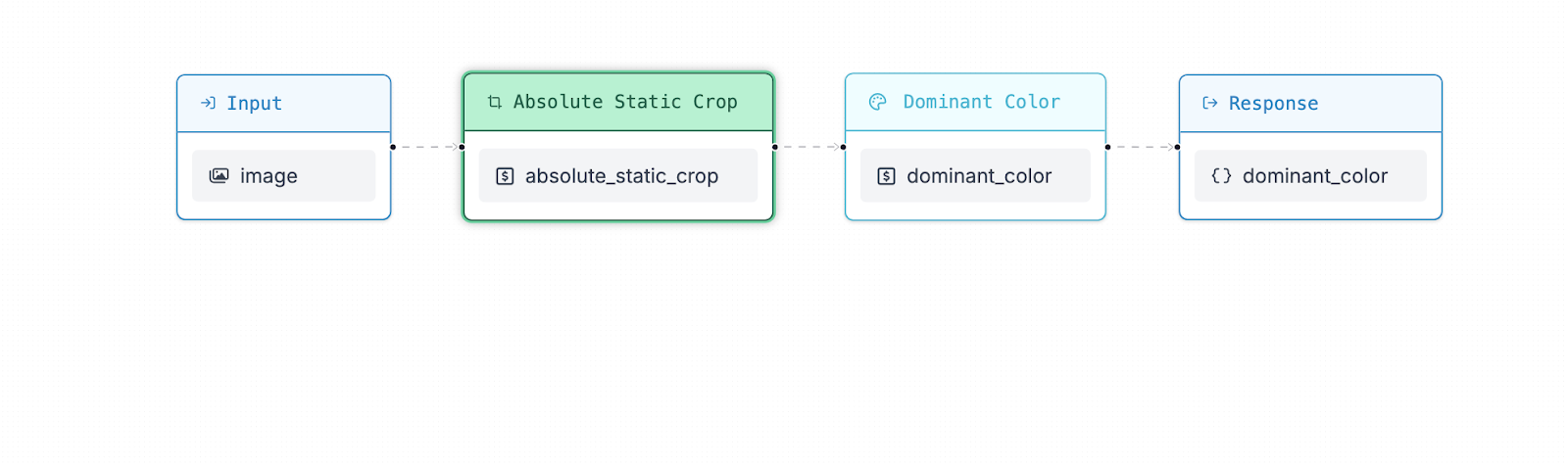
First, create a new Workflow in your Roboflow account:
Next, select the custom Workflow option.
Next, select Absolute Static Crop. This block allow us to focus our Workflow on a particular part of an image.
Next, insert the x y and width and height of the areas you are detecting. This should be the region of the screen that you want to blur.
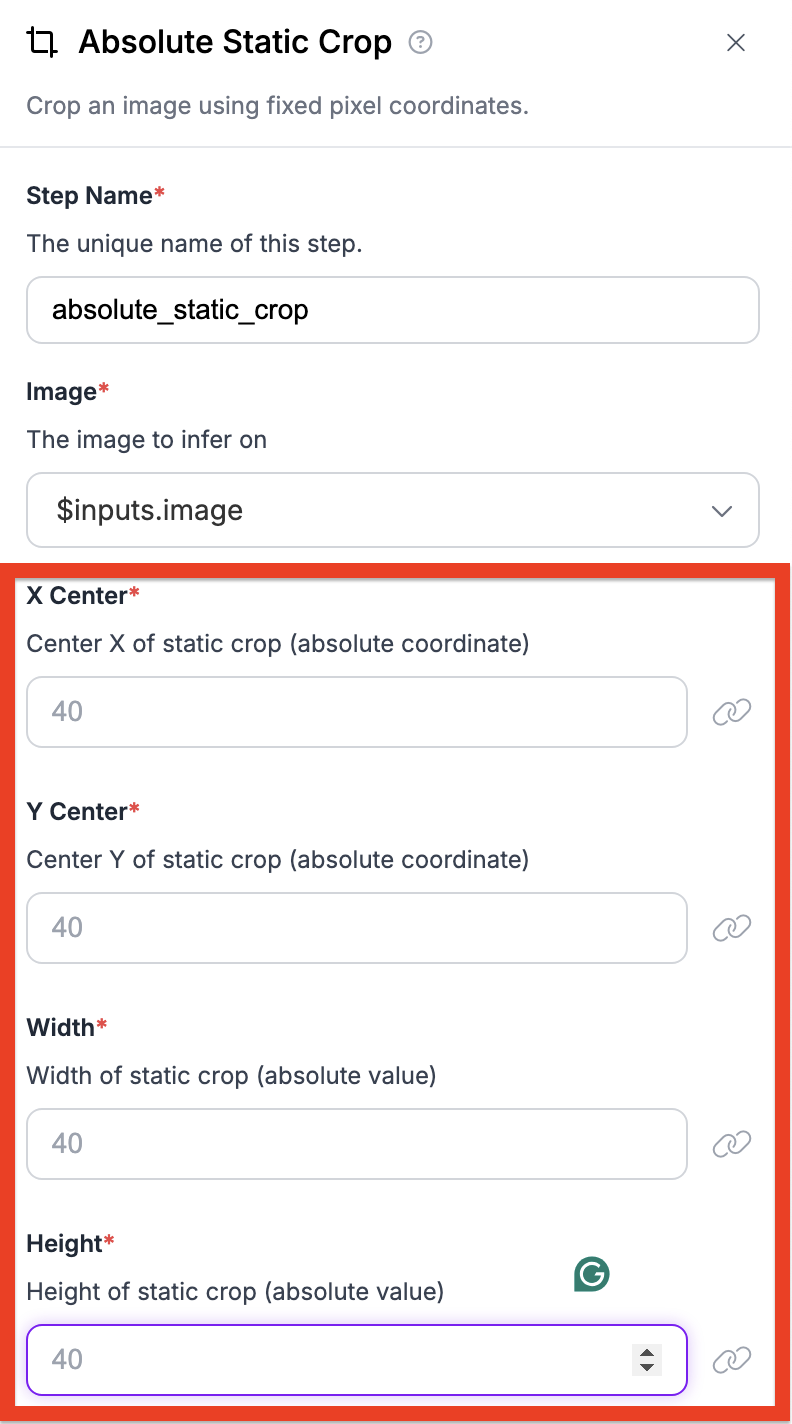
For my case, I used these values:
To retrieve these values, we recommend using a screenshot tool on your computer to identify the x, y, width, and height positions of the region you want to apply this tool to.
Next, add a dominant color block. You can find it by searching it up in the workflow search bar.
Make sure that the dominant color block accepts the static crop block as an input. Lastly, save the code block and save the deploy code.
In order to record our screen, we will need a virtual camera provider. In my case, I used OBS in order to capture my screen. We can set up the virtual camera on OBS by selecting the start virtual camera category in OBS.
Now that we have our virtual camera set up, we can finally start to code.
Before we begin to code, let's install the needed libraries.
Import the libraries into a new Python script:
Now we need to define the necessary variables. We will be using prev color in order to understand what the previous color is. We use blur_frame_count in order to count how many frames need to be blurred during the process.
Create blur function
Next, in order to blur the screen, we will be using the GaussianBlur function from the cv2 library. The region of interest (roi variable) will be the full image. During the function, for every frame blurred, we subtract the blurred frame count by 1.
Create prediction function
In this step, we will create a function that will look through each frame shown and depending on the current color and previous color, it will blur the next few frames. This function will utilize the outputs of our model in order to determine the color of each tab.
The full code snippet looks similar to this:
First, we set the prev_coor and blur_frame_count variables as global variables in order to access them in the function.
Then, we set the image.
Next, using our Workflow, we can get the dominant color of the tab. If the color difference is over 10, then we know that the tab has been switched. If this happens, we set the blur_frame_count to 3 and call the function blur_screen 3 times.
Lastly, we define the previous color of the screen and show the image, whether it is blurred or unblurred.
Import Workflow Code
Finally, we can add the Workflow code in order to connect the Workflow with the Prediction function.
Make sure to start the pipeline by running the following code.
Here is a demo showing our application in use:
In this guide, We learned how to blur tab changes in order to protect user privacy and information leakage. We also learned how to create a workflow in order to utilize traditional computer vision techniques. For more tutorials and guides utilizing workflows, check out some blogs .
Cite this Post
Use the following entry to cite this post in your research:
Nathan Yan . (Aug 30, 2024). How to Use Computer Vision to Blur Your Screen. Roboflow Blog: https://blog.roboflow.com/computer-vision-blur-screen/
Discuss this Post
If you have any questions about this blog post, start a discussion on the Roboflow Forum .
Growth Engineer @Roboflow! Learning, Writing, Coding...
Table of Contents
Computer vision, calculate the position of an object using computer vision, how to display an image in google colab, morphological operations in image processing, real-time zone monitoring with computer vision, mapping robot paths in robotics competitions with computer vision, how to build an automated multimodal data labeling pipeline.
- Educational Review
- Open access
- Published: 28 August 2024
Critical but commonly neglected factors that affect contrast medium administration in CT
- Michael C. McDermott ORCID: orcid.org/0000-0001-5628-3378 1 , 2 , 3 ,
- Joachim E. Wildberger 1 , 2 &
- Kyongtae T. Bae 4
Insights into Imaging volume 15 , Article number: 219 ( 2024 ) Cite this article
20 Altmetric
Metrics details
Past decades of research into contrast media injections and optimization thereof in radiology clinics have focused on scan acquisition parameters, patient-related factors, and contrast injection protocol variables. In this review, evidence is provided that a fourth bucket of crucial variables has been missed which account for previously unexplained phenomena and higher-than-expected variability in data. We propose how these critical factors should be considered and implemented in the contrast-medium administration protocols to optimize contrast enhancement.
This article leverages a combination of methodologies for uncovering and quantifying confounding variables associated with or affecting the contrast-medium injection. Engineering benchtop equipment such as Coriolis flow meters, pressure transducers, and volumetric measurement devices are combined with small, targeted systematic evaluations querying operators, equipment, and the physics and fluid dynamics that make a seemingly simple task of injecting fluid into a patient a complex and non-linear endeavor.
Evidence is presented around seven key factors affecting the contrast-medium injection including a new way of selecting optimal IV catheters, degraded performance from longer tubing sets, variability associated with the mechanical injection system technology, common operator errors, fluids exchanging places stealthily based on gravity and density, wasted contrast media and inefficient saline flushes, as well as variability in the injected flow rate vs. theoretical expectations.
There remain several critical, but not commonly known, sources of error associated with contrast-medium injections. Elimination of these hidden sources of error where possible can bring immediate benefits and help to drive standardized and optimized contrast-media injections.
Critical relevance statement
This review brings to light the commonly neglected/unknown factors negatively impacting contrast-medium injections and provides recommendations that can result in patient benefits, quality improvements, sustainability increases, and financial benefits by enabling otherwise unachievable optimization.
How IV contrast media is administered is a rarely considered source of CT imaging variability.
IV catheter selection, tubing length, injection systems, and insufficient flushing can result in unintended variability.
These findings can be immediately addressed to improve standardization in contrast-enhanced CT imaging.
Graphical Abstract

Introduction
For decades, intravenous (IV) contrast media have been used to aid in diagnostic imaging of anatomical structures. In Computed Tomography (CT), the use of an iodinated contrast medium enables visualization of and differentiation between tissue types with similar densities, due to the x-ray absorption properties of iodine [ 1 ]. While the absorption characteristics are favorable, the increased viscosity of iodinated contrast medium (which increases non-linearly with increasing concentration) makes hand injection or the use of traditional infusion pumps infeasible at the clinically relevant flow rates and volumes required. Therefore, the use of power injectors to administer contrast media is standard practice in CT [ 2 ]. The standard setup includes an electromechanical pump, a protocol programming interface, a location to attach fluid sources, and plastic disposables (either syringes and/or tubing sets) designed to deliver the fluids from the source through the IV access device to the patient [ 3 ].
Since the late 1990s, when Bae et al published the pioneering work with a predictive computer model for contrast-medium enhancement in CT, the research and clinical focus on optimizing contrast-medium injection protocols accelerated [ 4 , 5 , 6 ]. Aided by a combination of advances in scanner technology, the concern over post-contrast acute kidney injury, growing utilization and indications of CT in diagnostic workups, and the recent sustainability questions (e.g., ground-water contamination by waste or excreted IV contrast-medium), the general direction of the field has been towards reducing the amount of injected contrast-medium wherever possible via optimized injection protocols.
In the last 2–3 decades, radiology practices have made significant strides in injection protocol optimization. Faster acquisition times from newer scanner models have enabled the reduction of contrast-medium doses through shorter injection durations [ 7 , 8 , 9 , 10 , 11 , 12 , 13 , 14 , 15 ]. In many clinics, weight-based dosing modifications have overtaken a single fixed protocol used for every patient. The clinical introduction of low-kilovolt imaging (down to 70 kVp from 120 kVp reference) depending on patient habitus and indication has further enabled the reduction in contrast-medium doses, in some cases by 50% or more from the reference protocols [ 16 , 17 , 18 , 19 ]. In addition, as reconstruction algorithms continue to advance, noise levels are improving. This paired with the use of virtual monoenergetic images obtained via dual-energy or spectral CT at lower kilo-electron-volt levels further reduces the amount of contrast medium needed [ 20 ]. This downward trend of administered contrast-media volumes, while beneficial for patients and clinics alike, comes at the expense of reducing the margin for error. There are little reserves for unexpected and unforeseen variation during data acquisition, and even small variations will have bigger negative effects on enhancement levels of the CT scan. It is therefore of utmost importance to look into the different parameters which are of major impact.
In this article, we review and discuss the current state, in particular, critical but commonly neglected factors affecting contrast-medium administration in CT. We leverage a combination of varying methodologies for uncovering and quantifying these confounding variables, including engineering benchtop equipment (e.g., Coriolis flow meters, pressure transducers, and volumetric measurement devices) combined with small, targeted systematic evaluations querying operators, equipment, and the physics and fluid dynamics at play. In the end, we propose how these critical factors should be considered and implemented in the contrast-medium administration protocols to optimize contrast enhancement. As authors, we bring robust expertise with more than 50 years of combined experience in research of contrast-medium injections and nearly 10 years of experience in the engineering development of injector systems.
Factors determining contrast enhancement
Contrast-medium protocol optimizations were built on the foundational belief in a triad of relevant variables categorized by the early researchers: namely patient-related factors, CT-scan-related factors, and contrast-medium-injection-related factors. In this review, evidence is provided that a fourth bucket of crucial variables has been missed which account for previously unexplained phenomena and higher-than-expected variability in data (Fig. 1 ). While this new bucket does not have any direct impact on the factors of the other three, the factors from the well-known three buckets does directly affect the order or magnitude of the impact of the factors from the fourth bucket. This fourth bucket, if not understood and accounted for where possible, represents a barrier to further optimization of contrast-medium injection protocols.

Injection protocol optimization triad and the missing category of error-inducing variables that have a significant impact on the outcome of a contrast-enhanced diagnostic procedure
Selecting optimal IV catheters
The most common catheter gauge used in clinical practice is a 20-gauge (or 20 G), while 18 G may be used for higher flow rate applications, and 22 G or even 24 G may be used in more rare circumstances for small or difficult-to-access veins [ 21 ]. The gauge of the catheter represents the outside diameter of the device, with smaller numbers (e.g., 18 G) representing larger outer diameters. A common debate in clinics is which catheter gauge is appropriate for the desired flow rate. It is not uncommon for patients who come in with an existing IV access to have this switched to a bigger size to accommodate the higher flow rates needed for angiographic studies. This creates a certain amount of noncompliance and concern, especially among technicians operating the device and managing the patients. Fear of contrast-media extravasation drives much of this concern, and the tendency is toward larger catheter sizes for higher flow rate procedures even though this increases the likelihood of IV site pain and bruising for patients. This practice is fundamentally built on the belief that larger catheter sizes reduce injection pressure and enable higher flow rates.
While nearly all clinics are accustomed to looking at green, pink, blue, and yellow on the packages to select 18 G, 20 G, 22 G, and 24 G catheters (Fig. 2a ), this is actually the incorrect number upon which to base the selection of IV catheters for power injection. The correct number, as proposed here, is also published on the package by nearly all IV catheter manufacturers—the Gravity Flow Rate (Fig. 2b ). This is a standard measurement test that determines the flow rate at which water of a specific volume and head pressure will flow through the catheter under only the influence of gravity. This is an indirect measurement of the amount of pressure that the catheter will generate when fluid is injected through it, with higher gravity flow rates corresponding to lower pressures generated by injecting the same fluid at the same flow rate.

Critical factors to consider in the selection of IV catheter. a Various catheters color-coded according to their gauges, ( b ) an example of an IV catheter package with gravity flow rate highlighted, and ( c ) plots of injection pressure vs. catheter gravity flow rate for two different extremes of contrast-media (sub-datasets indicated with arrows) injected at 2, 4, 6, and 8 mL/s
To demonstrate the correlation of this number, the authors evaluated the 16 different IV catheters each with a different gravity flow rate (2 × 18 G, 10 × 20 G, 2 × 22 G, and 2 × 24 G) across 5 different catheter manufacturers. A power injector was used to deliver two different contrast media through each of the different IV catheters at four different flow rates (2, 4, 6, and 8 mL/s). The two different contrast media used were 300 mgI/mL (iopromide, Bayer AG, Berlin, Germany) and 400 mgI/mL (Iomeron, Bracco Imaging, Milan, Italy) at body temperature representing the two clinically relevant extremes of contrast-medium concentrations (and subsequent viscosities) used in CT. Figure 2c shows the graphs of injection pressure vs. catheter gravity flow rate for each of the tested injection flow rates.
The data points are color coordinated by catheter gauge, and it is clearly shown that there is a strong correlation (minimum R 2 = 0.9748) between injection pressure and IV catheter gravity flow rate with a decaying exponential relationship. This decaying exponential visually demonstrates the diminishing return at each flow rate of selecting any 18 G catheter over a high-performing 20 G. This is because the 20 G catheters with higher Gravity Flow Rates achieve roughly the same injection pressure as 18 G catheters (average difference of only 8 psi across all tested flow rates). In these cases, there is no additional clinical value in changing from the 20 G to the 18 G, and significant time, stress, and effort can be saved by the clinic.
In addition, as observed in Fig. 2 there is substantial variation in injection pressure within the same catheter gauges, especially among the 20 G (~ 60 psi). This highlights the importance of selecting an IV catheter with an optimized gravity flow rate, as ignoring this could result in unexpected performance degradation. This performance degradation includes CM injections aborted prematurely or delivered at a flow rate less than intended due to excessive pressure. This has the possibility of resulting in reduced image quality or non-diagnostic scans. This performance degradation can be mitigated by appropriate IV catheter selection. As demonstrated here, this selection should be based on the correct parameter that is relevant for performance: not catheter gauge and color but rather the gravity flow rate. As this becomes an economic-based purchasing decision, it is important to note that, to the best of the authors’ knowledge, the pricing and gravity flow rate are not causally linked for most manufacturers and therefore increasing performance likely will not be cost prohibitive. While a comparison of these results to previous studies would be ideal, an evaluation of 23,706 articles mentioning contrast-medium injections yields zero mentions of this parameter called Gravity Flow Rate for catheter selection.
Based on the data collected and experience, as a general rule, the authors recommend that 22 G catheters should have a gravity flow rate of at least 30 mL/min, 20 G should have at least 60 mL/min, and 18 G should have at least 95 mL/min. Selecting optimal IV catheters enables the minimization of injection pressure and maximization of achievable flow rates.
Long tubing degrades injection rates and dosing accuracy
In many CT suites, space can be limited, and the positioning of an injector system can be challenging due to its size. For some procedures, also the patient may need to be positioned on the table through one side of the gantry that the injector system cannot reach. To avoid these spatial constraints, many clinics prefer to use longer patient lines than the standard 250 cm offered by many manufacturers. Further, some clinics may choose to attach additional tubing sets to the distal end of the tubing to increase flexibility (e.g., additional stopcock or valve) or to save costs by off-label multi-patient use of the longer tubing set.
In these cases, there are two negative implications on performance and dosing accuracy. The first is that the longer tubing length increases the pressure of the injection under the same conditions as shorter tubing sets. This is a basic fluid dynamics principle known as pressure drop. This is defined by the Hagen-Poiseuille equation, where the length of the tubing set is inversely proportional to the flow, however, under constant flow with a larger length, the pressure must increase correspondingly.

To demonstrate the impact of the longer patient lines on achievable flow rates, four different sizes were tested starting with the standard 250 cm and increasing every 50 cm up to 400 cm. Two different contrast media with different viscosities representing the clinically significant range of available contrast-media concentrations (300 mgI/mL and 400 mgI/mL) were injected up to a maximum rate before the injection system reached the pressure limit. In this case, the 300 mgI/mL was injected at room temperature and the 400 mgI/mL was injected at body temperature to reflect more common clinical practice. This maximum rate was recorded and compared across the different tubing set lengths as shown in Fig. 3 . The increase of 150 cm from the standard length led to a corresponding decrease in achievable flow rates by 55% for the 400 mgI/mL and 40% for the 300 mgI/mL.

Plot of maximum achievable flow rate vs tubing length at two different conditions. The maximum achievable flow rate declines with an increase in the length of the tubing set obtained with two different contrast media at two different temperatures (RT, room temperature)
This significant decrease in achievable flow rates and the corresponding increase in pressure at constant flow rates has direct clinical implications. Reduction in achievable flow rates can limit the capability to deliver high iodine delivery rates necessary for angiographic studies, especially on larger patients. Also, the increase in injection pressure increases the negative effects on dosing accuracy, which are described in the following sections. While a comparison of these results to previous studies would be ideal, there is no existing literature that could be found that evaluates the impacts of tubing length on performance in CM injections.
It is recommended that every clinic evaluate any opportunity to position the injection system closer to the patient to reduce the need for the use of longer tubing sets. Although this may be impractical in some setups depending on the room design and the patient positioning within the scanner, attention should be paid to reducing the need for longer patient lines where possible.
Injector mechanical systems affect contrast-medium delivery
The benefits of power injection systems in their ability to deliver higher flow rates and volumes in a more consistent manner than hand injections do not come without compromises. While it is obvious to view injection systems mainly along the lines of cost, features, accessories, and performance specifications (e.g., maximum flow rates and maximum pressure limits), the more important aspect when it comes to performance and the contribution to consistent image quality are the plastic disposables material and geometry combined with the mechanism of delivery. A number of injectors available in different brands and classifications on the market fall into one of three categories: piston-based, peristaltic pump, or hydraulic. Piston-based injectors load fluid into syringes or reservoirs which are then expelled through tubing sets into the patient by a piston/plunger (otherwise thought of as an automated hand syringe). Peristaltic pumps use rotational motion to pinch and un-pinch sections of a tube which draw fluid from a supply and inject it into the patient through an additional tubing set. Hydraulic injectors use fluid external pressure on a collapsible reservoir to compress the reservoir at a controlled rate and expel the fluid into the tubing sets to be delivered to the patient.
A problem common to all manufacturers regardless of delivery mechanism, is that the plastic disposables swell and stretch under the internal loads of the high injection pressures. This swelling and stretching is dependent upon temperature, injection pressure, reservoir volume or tubing volume, and material properties of the plastic. The loads at high injection pressures can be extreme for thin and flexible plastics to endure; for context, 300 psi of pressure in an example syringe can equate to 800 lbs or 363 kg of force pressing on every surface of the plastic. Figure 4 illustrates a mathematical simulation generated in this study of the non-linear expansion of the plastic disposables from an example piston-based injection system. In this simulation, the plastic disposables under high injection pressure can expand up to 10 mL in extra internal volume. The worst case as measured by the authors is on a hydraulic injection system with nearly 50 mL of additional volume swelling. By Conservation Law, this means that during an injection, while the expectation is that fluid is being delivered to the patient, the reality is that much of the volume is actually being injected into the expanding plastic disposables. This creates an unexpected delay in delivery of the bolus which is non-linear and dependent upon injection pressure. As the plastic disposables are elastically deforming under pressure but have not yielded into a new shape, when the pressure is relieved at the end of the injection the disposables decompress, expelling the extra trapped volume into the patient at a decaying rate.

Mathematical simulation illustrating the effect of expanding plastic disposables. “Compliance” is affected by both the tubing set volume and pressure.
The clinical implications of this factor are two-fold. First, the trapped volume from the expanding disposables is not a contributor to the main bolus of the injection, as this volume is only released when the injection pressure is relieved (partially during the saline flush and the remaining volume at the end of the injection). Therefore, the desired iodine delivery rate is not achieved for the intended duration, and the total effective iodine load (contributing to parenchymal enhancement) administered is likely less than intended. This phenomenon was measured using a real-time Coriolis density and flow meter (consistent with previous literature for assessing injected iodine concentrations), with the results from an example injection of CM with an iodine concentration of 370 mgI/mL (with a viscosity representing the middle of the range of available contrast-medium) at 4 mL/s for 40 mL as shown in Fig. 5 . This was repeated with a piston-based injector and a peristaltic injector to simulate the two configurations with the most significantly different disposables designs. This figure displays the injected concentration over time entering the patient’s circulation. The magnitude of the shaded region at the beginning of the injection is a direct correlation to the expansion of the plastic disposables. The shape of the shaded region at the end of the injection is a combination of decompression of the plastic disposables as well as the efficacy of the saline flush in eliminating the contrast medium remaining in the tube. This latter contributor will be discussed in more detail below.

Concentration-time plot of ideal versus empirical injected flow rates for a single-phase injection. The shaded area represents the deviation between the ideal (dotted line) and empirical (solid curves measured from two different systems) injected flow rates as caused by confounding factors like plastic disposables expansion
The second clinical implication is that the enhancement achieved in a target body region will vary significantly even with the exact same injection protocol for the exact same patient as long as any variable is changed that affects injection pressure (and therefore disposables expansion) [ 4 , 5 , 6 ]. These variables include contrast-media viscosity, length and diameter of the tubing sets used, size/type of IV access device, etc. This holds true even if the exact same injection system itself is used. When adding in the different types of injection systems, the inconsistency may be even more substantial.
Figure 6 shows the contrast-medium and saline distribution profiles at two different injection protocols delivered across four different clinical setups with varying injection systems, contrast media viscosity, and IV catheter. The greyscale shading over time is directly correlated to the injected concentration of the fluid (equivalent method as described above). Each of the four different setups used a different injection system (two piston-based, two peristaltic-pump) configured each with a contrast-medium of constant concentration (370 mgI/mL) but different viscosity (5 cP, 12 cP, 17 cP, 22 cP), and each with a different IV catheter gauge and gravity flow rate (18 G 105 mL/min, 20 G 65 mL/min, 20 G 42 mL/min, 22 G 36 mL/min).

Contrast-medium and saline distribution profiles at two different injection protocols delivered on four different injection systems (two piston-based, two peristaltic pumps). The two injection protocols are shown in the header of the figure. The greyscale shading over time correlates with the injected concentration of the fluid as measured just proximal to the IV access device for each setup
The general expectation from clinicians would be that the delivered output of the CM to the patient would be roughly identical. As shown in the figure, even with an identical contrast-medium injection protocol, the output as delivered by the different setups is significantly altered from the expectation. Note that these variations are measured at the catheter site prior to the patient and represent variability in the input function. The variability introduced by patient-related factors has not yet even been added to the equation at this stage.
Because of the variable contrast-medium delivery caused by the plastic disposables expansion and injector mechanism, the seemingly same injection protocol would yield significantly different contrast enhancement. Unfortunately, there is no easy fix for this that can be attempted from the side of practicing clinicians. To compensate for this, the manufacturers of the disposables would need to significantly increase the strength of the materials used which adds substantial cost that would be economically unviable. The other alternative is to use mathematical modeling to predict the expansion of the disposables under given conditions and to compensate for this in real-time. In whichever way this previously undiscussed phenomenon is to be addressed, there is no clear-cut solution for everyday clinical practice at the moment.
Improper injector setup causes under-dosing
When using a piston-based injector system with syringes, benefits have been shown including the ability to deliver more consistent flow than peristaltic pump-based systems as well as higher achievable iodine delivery rates [ 3 , 13 ]. These benefits do not come without tradeoffs, which can easily be compensated for if they are understood. The key operating step of some piston-based systems that leads to the most common operator error is on filling of the syringes or reservoirs. For systems that allow the user to manually fill the syringes by retracting the piston, at the end of the filling process, if the plunger is not manually driven forward far enough, the system may under-deliver the corresponding fluid. This is due to the fact that all mechanical systems have slack in them. When the plunger is driven backward to fill the syringes, the many different mechanical components pull against each other and compress. This creates small gaps between the different components. If the plunger is not then correspondingly driven forward a sufficient amount to close these gaps, when the injection starts there will be a motion of the piston forward that does not result in displacement of the fluid out of the syringe and into the patient. This is shown in Fig. 7 . On many syringe-based systems, every 0.5–0.75 mm of linear motion corresponds to 1 mL of fluid. Therefore every 0.5–0.75 mm of mechanical slack that is not accounted for will result in 1 mL of under-delivered volume vs. the programmed protocol. This is known by manufacturers and has been accounted for with automated filling features, however, many operators still use the manual filling options.

Example diagram showing where slack can be observed in a typical piston-based injection system
A small observational study of 20 patient procedures performed by technical staff in the author’s clinic yielded an average under-delivered volume of 3.6 mL ± 3.2 mL per injection with a maximum of 12 mL. After discussion with the technical staff about the unintended error and a small change to the operating procedure to either use automatic filling features or to ensure that the plunger has been pushed forward after manual filling, the average under-delivered volume decreased to 0.0 mL with no observable cases of the error in the study.
Although this may be a smaller magnitude, an average of 3.6 mL in contemporary procedures may represent 5–10% of the total injected contrast-medium volume depending on the indication. A maximum of 12 mL represents an even more significant portion of the intended contrast-medium volume injected. This previously unknown error was likely accounted for in the empirical determination of the site-specific contrast injection protocol, and variation is likely masked by blaming image quality implications on patient-related factors or scan timing. This is the first evaluation of its kind in literature to the best of the author's knowledge, therefore comparison to existing literature is unfortunately not possible.
It is recommended that radiographer/technician staff evaluate the variability in the setup of the injection systems among their teams and agree upon a standard operating procedure. This should be checked using water and a weighing scale or a simple graduated cylinder to ensure the volumetric accuracy of the first injection after setup.
Contrast-medium stealthily trades places with saline
Iodinated contrast media and saline solution (NaCl) are significantly different in both viscosity and density. The density of iodinated contrast medium is typically between 1.3 and 1.45 g/cm 3 , while the density of saline is approximately 1.0 g/cm 3 . In normal clinical practice (excluding pediatric patients and neonates where minimizing injected volume is critical), NaCl solution is typically used to prime the tubing sets prior to injection. The volume of these tubing sets can be between 5 and 26 mL in volume depending on the manufacturer and length. The tubing sets are typically positioned such that the fluid source at the level of the operator is higher than the end of the tubing set which is closer to the ground. Because of their difference in density, the heavier contrast that is either in the fluid supply or in the syringes will exchange places with the saline in the tubing set. In particular, the impacts of density and gravity immediately take effect in an “open system”: that is, in piston-based systems where there are no stopcocks or check valves attached to the syringes, or in peristaltic-pump systems when the different fluid supply lines are intermittently open to each other as pinch valves change position, Fig. 8 shows an image of the layering of the fluids as the contrast-medium is dyed green for visualization. The saline that was used to prime the tubing sets will flow upward into the contrast-medium supply and the contrast-medium will instead fill the tubing set. An average-sized tubing set that is 10 mL in volume has been observed to trade places in less than 30 s under normal conditions.

A tubing set showing contrast-medium trading places with saline in (left) a large field of view and (right) a magnified view at the interface of the contrast-medium and saline. The contrast medium (dyed in green) filled in the reservoirs migrates downward to trade places with saline as the density of the contrast medium is greater. The magnified view with arrows reveals that the two fluids layer and slide past each other with no other driving force besides gravity
The clinical implication is that 10 mL of contrast medium is delivered more than intended, as the saline from the tubing set floats to the top of the contrast supply. The secondary consequence of this is that over the course of the day, the contrast-medium supply will become gradually more and more diluted. Therefore, the end effect is that early patients when the contrast-medium supply is first filled will receive an unexpectedly high dose. The last patient for that contrast-medium supply will receive an unexpectedly low dose as it has been diluted over time. Based on the known tubing set volumes from available manufacturers, the magnitude of this over-delivery in a worst-case scenario can reach 26 mL. Last, if the contrast-media bolus starts at the end of the tubing, instead of the beginning, the timing of the arrival of the contrast-media will be different from expectations and could affect image quality. To the best of the author's knowledge, this is the first mention of this phenomenon in the literature.
It is recommended that clinics ensure their staff are not leaving the tubing sets (when open systems are in use) in a position where they hang lower than the fluid supplies on the injector system.
Insufficient saline flush wastes contrast media
Several studies have been conducted evaluating the performance of a saline chaser, which was predominantly introduced into clinical practice to flush the otherwise wasted contrast medium from the tubing set and the peripheral veins of the patient into systemic circulation [ 22 , 23 ]. Evidence also suggests that a saline chaser keeps the contrast bolus more compact and enables higher peak attenuation and less bolus dilution through the pulmonary circulation and the capillary effects of the lungs [ 24 ].
When we determine an adequate amount of saline chase, there are important considerations to keep in mind in view of the injection fluid dynamics which is influenced by the differences in the viscosity and density between contrast-medium and saline. The saline chaser does not push the contrast-medium forward like solid objects, i.e., plug flow. Rather, the thin fluid of saline chaser mixes and shears through the thick center layers of contrast-medium, thereby leaving a boundary layer of contrast-medium behind stuck to the walls of the tubing set. The larger the chaser volume at a constant flow rate, the less contrast medium is left behind in the tubing set. Also, the higher the saline chaser flow rate, the more turbulent the flow becomes, and the less contrast medium is left behind in the tubing set at the same chaser volume with a lower flow rate. Figure 9 demonstrates the fluid dynamics phenomena of the boundary layer at three different time points after the initiation of the saline flush.

Boundary layer phenomena between saline and contrast-medium in a tubing cross-section at four time points. The central blue region represents saline chaser, while the peripheral green region represents contrast-medium. Insufficient saline chasers would fail to completely clear the residual layers of contrast-medium
To quantify this phenomenon, an experimental study was conducted using contrast media of varying viscosities and concentrations (300 mgI/mL, 320 mgI/mL, 350 mgI/mL, 370 mgI/mL, and 400 mgI/mL). The contrast media were filled into a standard 250 cm tubing set and saline flushes of varying volumes and flow rates were pushed through the tube with a power injector. The same Coriolis meter previously discussed was used to measure the concentration of the fluid exiting the tubing set. A flush was considered 100% successful when the density/concentration of the fluid exiting the tubing set reached that of the 0.9% NaCl solution used as the flush (each test was repeated three times enabling standard deviations to be calculated). Figure 10 shows the compiled results across all tested contrast-medium concentrations with averages for flow rates below 4 mL/s and at or above 4 mL/s. A threshold of 4 mL/s was selected as this is the transition point from laminar to turbulent flow for NaCl solution in a standard tubing set, which significantly affects the capability to flush contrast media from the boundary layer. This is evidenced in the figure below with significant differences in minimum flush volume above and below this flow rate threshold.

Plot of the minimum saline flush volume required to clear contrast media of different concentrations at flow rates below 4 mL/s or at and above 4 mL/s. A higher volume of saline flush is required to clear contrast media of higher concentration injected at a lower rate
Comparing these results with the usual clinical practice where saline flush volumes are between 20 and 40 mL on average and flow rates outside of CTA procedures are typically below 4 mL/s, it is expected that there is significant wasted contrast media unknowingly being discarded within the tubing sets. When evaluating contrast-medium volumes left in the tubing set after 30 mL of a saline flush, the average volume wasted was 1.4 mL with a minimum of 0.3 mL and a maximum of 3.8 mL. This was measured by differences in weight measured on a highly accurate scale and calculating the volume based on measured contrast-medium density. In the clinic of the authors, this corresponds to a waste of 22.5 liters of contrast media each year. This drives concern from both an economical and an environmental perspective. The higher the concentration/viscosity of the contrast medium, the increase in the wasted contrast medium thrown away after the saline flush. Further, as discussed above, the increase in the length of the tubing set compounds this issue further and increases the minimum volume of flush needed to successfully remove all contrast media from the tubing.
An additional element of concern is performance degradation. The less effective the saline flush is at removing the contrast media from the tubing, the further separated that residual contrast media becomes from the main bolus that has already entered the circulatory system of the patient. In dynamic studies where iodine delivery rate and bolus compactness are critical metrics contributing to attenuation, insufficient saline flush results in larger volumes of contrast media intended to be part of the main bolus that instead lag too far behind to provide diagnostic relevance, or never enter the patient at all and is discarded in the tubing set.
It is recommended that clinics evaluate their current saline flush volumes as part of the set injection protocols. A simple mechanism to observe whether contrast-medium is left behind in the tubing set is to put the used tubing in the scanner prior to discarding and to scan at 70–90 kVp. Any contrast medium present in the tubing set will be visible and suggest that the flush volume is insufficient. To the best of the authors’ knowledge, while saline flush volumes have been sporadically evaluated in the literature, the efficacy of the saline flush to clear the contrast media has not been previously investigated.
Deviation from the programmed injection flow rate
The widely unknown physical phenomena mentioned above like plastic disposables expansion and fluid property differences of contrast-medium and saline also contribute to unexpected variations in flow rate. Power injection systems are believed to deliver consistent flow rates and volumes at high pressures beyond what is possible from human hand injection. However, from the information provided by the injector manufacturers on the user interfaces, it is not possible to audit whether this flow rate and delivered volume are truly consistent. As seen from the examples above, there are many cases where the expected delivered volume can vary greatly from reality, however, no indication of this is provided. The same is true with flow rates. For example, peristaltic injectors deliver fluid by roller pumps constantly pinching and un-pinching tubing to drive fluid forward. This action results in sinusoidal flow rate variation that significantly deviates from expected, as was proven by Chaya et al [ 25 ]. A representation of these findings also confirmed in this study is shown in Fig. 11 .

Flow rate fluctuations from the ideal profile in three different by injection systems. a Flow rate fluctuations with a peristaltic-based injection (black curve). b Flow rate fluctuations with a piston-based injection with a transitional drop in flow rate at the switch of contrast-medium to saline (green curve). c Flow rate fluctuations with a piston-based injection with lower effect of plastic disposables compliance (blue curve).
While this flow rate variation occurs on peristaltic systems, unexpected variations in flow rates also occur on piston-based and hydraulic systems, albeit a lesser magnitude. At the transition between contrast-medium and saline flush, there is a significant momentum change when the lower viscosity fluid reaches the catheter. This results in a drop in pressure that is visible on the pressure graph on the injector display. However, when the pressure decreases rapidly, the plastic disposables also decompress, with this decompression forcing additional fluid out of the system. This causes a momentary variation in flow rate that can deviate significantly from what is expected (Fig. 11 ), This phenomenon is made worse with higher viscosity contrast-medium, as the change in pressure is significantly higher. Although these fluctuations in flow rate likely have little clinical impact on image quality as the deviation is smoothed out by the capacitive effect of the lungs (note: dynamic imaging of the pulmonary arterial vessels may be impacted), further studies are warranted to investigate the effect of the flow rate deviations caused by injector systems on IV catheter displacement and subsequent extravasation.
Summary and recommendations
As shown here in this paper, there are many different factors associated with the contrast-medium injection that are not widely known or understood, from equipment selection to operator variability and also fluid dynamics. Although these factors can contribute to significant error and variability in the quality and consistency of contrast-medium delivery, they were rarely investigated or addressed in the design and implementation of injection protocols. When contrast enhancement is unexpectedly suboptimal, we often blame intrinsic patient factors or are just puzzled without knowing what to do. Understanding these critical but commonly neglected technical factors is an opportunity for wider awareness and correction where possible. There are two main reasons for this. The first is that as technology continues to advance, contrast-medium volumes per procedure continue to be driven lower. With lower procedure volumes, the sources of error that in the past were single-digit percent errors and easily missed will become substantial sources of error within the procedure. Wasted contrast-media volumes that could otherwise be optimized will have a greater effect on image quality consistency. This waste drives not just quality challenges but also unnecessary costs and negative impacts on sustainability. In a time where contrast-medium shortages drive significant stress within hospital systems, responsible use of contrast-medium is highly recommended.
There are simple steps that can be taken to address many of the sources of error/waste identified in the paper (Table 1 ). The authors recommend evaluation of the gravity flow rate of the catheters in use, switching to the use of shorter tubing sets where appropriate, and assessment of the quality and consistency in the value chain of contrast-enhanced exams; from the injection system and contrast-media to the operators and handling/setup procedures in clinical practice. Elimination of these hidden sources of error can bring immediate benefits while paving the way for the future where predictive modeling as introduced by Bae et al decades ago can be reasonably implemented in the clinic to drive standardized and fully optimized contrast-media injections that have so far eluded us.
Data availability
All data generated in the context of this article are freely available upon request made to the corresponding author.
Abbreviations
- Intravenous
Peak kilovolt
Saline solution
Maschera L, Lazzara A, Piergallini L et al (2016) Contrast agents in diagnostic imaging: present and future. Pharmacol Res 110:65–75
Article Google Scholar
Shuman WP, Adam JL, Schoenecker SA et al (1986) Use of a power injector during dynamic computed tomography. J Comput Assist Tomogr 10:1000–1002
Article CAS PubMed Google Scholar
McDermott MC, Kemper CA, Barone W et al (2020) Impact of CT injector technology and contrast media viscosity on vascular enhancement: evaluation in a circulation phantom. Br J Radiol 93:20190868
Article PubMed PubMed Central Google Scholar
Bae KT (2010) Intravenous contrast medium administration and scan timing at CT: considerations and approaches. Radiology 256:32–61
Article PubMed Google Scholar
Bae KT, Heiken JP, Brink JA (1998) Aortic and hepatic contrast medium enhancement at CT. Part I. Prediction with a computer model. Radiology 207:647–655
Bae KT, Heiken JP, Brink JA (1998) Aortic and hepatic peak enhancement at CT: effect of contrast medium injection rate-pharmacokinetic analysis and experimental porcine model. Radiology 206:455–464
Cormack AM (1980) Early two-dimensional reconstruction (CT scanning) and recent topics stemming from it. J Comput Assist Tomogr 4:658–664
Hounsfield GN (1980) Nobel prize lecture: computed medical imaging. J Comput Assist Tomogr 4:665–674
Kalender WA, Seissler W, Klotz E et al (1990) Spiral volumetric CT with single-breath-hold technique, continuous transport, and continuous scanner rotation. Radiology 176:181–183
Lell MM, Kachelrieß M (2020) Recent and upcoming technological developments in computed tomography: high speed, low dose, deep learning, multienergy. Invest Radiol 55:8–19
Wildberger JE, Prokop M (2020) Hounsfield’s Legacy. Invest Radiol 55:556–558
Willemink MJ, Noël PB (2019) The evolution of image reconstruction for CT—from filtered back projection to artificial intelligence. Eur Radiol 29:2185–2195
Schöckel L, Jost G, Seidensticker P et al (2020) Developments in x-ray contrast media and the potential impact on computed tomography. Invest Radiol 55:592–597
Alkadhi H, Euler A (2020) The future of computed tomography: personalized, functional, and precise. Invest Radiol 55:545–555
Ginat DT, Gupta R (2014) Advances in computed tomography imaging technology. Annu Rev Biomed Eng 16:431–453
Kok M, Mihl C, Mingels AA et al (2014) Influence of contrast media viscosity and temperature on injection pressure in computed tomographic angiography: a phantom study. Invest Radiol 49:217–223
De Santis D, Caruso D, Schoepf JU et al (2018) Contrast media injection protocol optimization for dual-energy coronary CT angiography: results from a circulation phantom. Eur Radiol 28:3473–3481
Kok M, Mihl C, Hendriks BM et al (2016) Optimizing contrast media application in coronary CT angiography at lower tube voltage: evaluation in a circulation phantom and sixty patients. Eur J Radiol 85:1068–1074
Mihl C, Wildberger JE, Jurencak T et al (2013) Intravascular enhancement with identical iodine delivery rate using different iodine contrast media in a circulation phantom. Invest Radiol 48:813–818
Higashigaito K, Mergen V, Eberhard M et al (2023) CT angiography of the aorta using photon-counting detector CT with reduced contrast media volume. Radiol Cardiothorac Imaging 5:e220140
Johnson PT, Christensen G, Lai H, Eng J, Fishman EK (2014) Catheter insertion for intravenous (IV) contrast infusion in multidetector-row computed tomography (MDCT): defining how catheter caliber selection affects procedure of catheter insertion, IV contrast infusion rate, complication rate, and MDCT image quality. J Comput Assist Tomogr 38:281–284
Haage P, Schmitz-Rode T, Hübner D et al (2000) Reduction of contrast material dose and artifacts by a saline flush using a double power injector in helical CT of the thorax. AJR Am J Roentgenol 174:1049–1053
Article CAS Google Scholar
Irie T, Kajitani M, Yamaguchi M, Itai Y (2002) Contrast-enhanced CT with saline flush technique using two automated injectors: how much contrast medium does it save? J Comput Assist Tomogr 26:287–291
Schoellnast H, Tillich M, Deutschmann HA et al (2003) Abdominal multidetector row computed tomography: reduction of cost and contrast material dose using saline flush. J Comput Assist Tomogr 27:847–853
Chaya A, Jost G, Endrikat J (2019) Piston-based vs peristaltic pump-based CT injector systems. Radiol Technol 90:344–352
Download references
No funding sources outside of Maastricht University Medical Center were used in the conduct of this research and the writing of this article.
Author information
Authors and affiliations.
Department of Radiology & Nuclear Medicine, Maastricht University Medical Center + , Maastricht, The Netherlands
Michael C. McDermott & Joachim E. Wildberger
CARIM School for Cardiovascular Diseases, Maastricht University, Maastricht, The Netherlands
Bayer AG, Berlin, Germany
Michael C. McDermott
Department of Diagnostic Radiology, Li Ka Shing Faculty of Medicine, The University of Hong Kong, Hong Kong, Hong Kong
Kyongtae T. Bae
You can also search for this author in PubMed Google Scholar
Contributions
M.C.M. conducted the necessary research and data acquisition under the supervision of J.E.W. and K.T.B. M.C.M., J.E.W., and K.T.B. equally contributed to the drafting of the manuscript.
Corresponding author
Correspondence to Michael C. McDermott .
Ethics declarations
Ethics approval and consent to participate.
Not Applicable.
Consent for publication
Competing interests.
M.M. is affiliated with Bayer AG. The remaining authors declare that they have no competing interests.
Additional information
Publisher’s Note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
McDermott, M.C., Wildberger, J.E. & Bae, K.T. Critical but commonly neglected factors that affect contrast medium administration in CT. Insights Imaging 15 , 219 (2024). https://doi.org/10.1186/s13244-024-01750-4
Download citation
Received : 27 December 2023
Accepted : 16 June 2024
Published : 28 August 2024
DOI : https://doi.org/10.1186/s13244-024-01750-4
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Contrast media
- Injection systems
- Computed tomography
IMAGES
VIDEO
COMMENTS
Variables are the building blocks of scientific inquiry, representing the factors or characteristics that can change or vary within an experiment or study. A deep understanding of variables is crucial for designing, conducting, and analyzing research effectively. In this article, we break down the complex concept of variables in scientific research, offering insights into their roles and ...
This article provides examples of variables on climate change, academic performance, crime, fish kill, crop growth, and viral content.
Types of Variables in Research Types of Variables in Research are as follows: Independent Variable This is the variable that is manipulated by the researcher. It is also known as the predictor variable, as it is used to predict changes in the dependent variable. Examples of independent variables include age, gender, dosage, and treatment type. Dependent Variable This is the variable that is ...
The independent variable is the cause. Its value is independent of other variables in your study. The dependent variable is the effect. Its value depends on changes in the independent variable. Example: Independent and dependent variables. You design a study to test whether changes in room temperature have an effect on math test scores.
Learn about the most popular types of variables in research, including dependent, independent and control variables - as well as mediating, moderating and co...
Learn about the most popular variables in scientific research, including independent, dependent, control, moderating and mediating variables.
Independent and dependent variables are crucial elements in research. The independent variable is the entity being tested and the dependent variable is the result. Check out this article to learn more about independent and dependent variable types and examples.
Independent variables are frequently called different things depending on the nature of the research question. In predictive questions where a variable is thought to predict another but it is not yet appropriate to ask whether it causes the other, the IV is usually called a predictor or criterion variable rather than an independent variable.
This guide discusses how to identify independent and dependent variables effectively and incorporate their description within the body of a research paper.
Types of Variables in Research and Their Uses (Practical Research 2) PHILO-notes 175K subscribers 94K views 2 years ago
Learn about using independent and dependent variables in research studies, discover how to tell what type a variable is and review examples of both in studies.
Operationalize a Variable: A Step-by-Step Guide to Quantifying Your Research Constructs Operationalizing a variable is a fundamental step in transforming abstract research constructs into measurable entities. This process allows researchers to quantify variables, enabling the empirical testing of hypotheses within quantitative research. The guide provided here aims to demystify the ...
The research variable is a quantifying component that may change from time to time. In research, variables are like the building blocks that help us understand relationships between different factors. In this article, iLovePhD explains the main types of variables and what they mean with some real-world examples.
This is a research methodology that involves the manipulation of one or more independent variables to observe their effects on a dependent variable. Experimental research is often used to study cause-and-effect relationships and to make predictions.
Compare and contrast the major research designs. Explain how to judge the quality of a source for a literature review. Compare and contrast the kinds of research questions scientists ask. Explain what it means for an observation to be reliable. Compare and contrast forms of validity as they apply to the major research designs.
Independent variable: a variable that stands on its own and aren't affected by anything that you, as a researcher, do. Simple definition, in depth examples.
Research constructs and variables both relate to the things of interest that you're going to explore within your study. For example, let's say you're interested in job satisfaction and more specifically you're interested in what factors impact an employee's job satisfaction. In this case, both job satisfaction and all of those things, those ...
A simple explanation of extraneous variables, including a formal definition and several examples.
The authors note that an easy way to identify the independent or dependent variable in an experiment is: independent variables (IV) are what the researchers change or changes on its own, whereas ...
CUU Answer booklet QUESTION 1 A] 'The impact of child abuse on children's performance at school in Uganda. Case study Wakiso district.' Independent variable is a variable that stands alone and isn't changed by the other variables you are trying to measure while a dependent variable is a variable or something that depends on other factors. Hence, the independent and dependent variables of this ...
How To Make Conceptual Framework: 4 Steps. 1. Identify the Important Variables of Your Study. There are two essential variables that you must identify in your study: the independent and the dependent variables. An independent variable is a variable that you can manipulate. It can affect the dependent variable.
In the realm of research, particularly in mathematics and the sciences understanding the concept of the variables is fundamental. The Variables are integral to the formulation of hypotheses the design of the experiments and interpretation of data. They serve as the building blocks for the mathematical models and statistical analyses making it possible to describe, analyze and predict phenomena.
1. Start with a broad topic. A broad topic provides writers with plenty of avenues to explore in their search for a viable research question. Techniques to help you develop a topic into subtopics and potential research questions include brainstorming and concept mapping.
Make sure that the dominant color block accepts the static crop block as an input. Lastly, save the code block and save the deploy code. Set Up OBS. In order to record our screen, we will need a virtual camera provider. In my case, I used OBS in order to capture my screen. We can set up the virtual camera on OBS by selecting the start virtual ...
Past decades of research into contrast media injections and optimization thereof in radiology clinics have focused on scan acquisition parameters, patient-related factors, and contrast injection protocol variables. In this review, evidence is provided that a fourth bucket of crucial variables has been missed which account for previously unexplained phenomena and higher-than-expected ...